https://www.lairdstewart.com/Laird Stewart's blog2026-05-22T00:00:00ZLaird Stewartresources/icon.pnghttps://www.lairdstewart.com/blog/no-free-lunch-software.htmlThere's no free lunch in software2026-05-22T00:00:00Z
Scott Sumner wrote a good post earlier this month on the
usefulness of tautologies
which got me thinking about tautologies in software development. One which
came to mind is
"To reduce intrinsic complexity of a program one must reduce the
complexity of the problem it's solving"
I liken this to the no free lunch theorem (hence the title of this post)
because when designing ML algorithms, you can only improve performance by
limiting the set of problems under consideration (i.e., making assumptions
about the problem at hand). Similarly, in software, you can only simplify
code by making simplifying assumptions about the problem you're solving.
So what can we learn from this tautology? If you believe that software
developers should strive for simplicity (as John Ousterhout argues in
"A Philosophy of Software Design"), then you must also believe software developers should focus on making
assumptions.
What are assumptions to a software engineer? Assertions, preconditions,
and API contracts! We should therefore strive to write methods that looks
like
/**
* Assumes that bar() was called first.
*/
public void foo(Key key)
{
Preconditions.checkArgument(key != null);
Preconditions.checkArgument(cache.contains(key));
Preconditions.checkState(isCacheInitialized());
...
}
with the understanding that it will simplify the final program. I've
recently found myself writing more and more methods that look like this.
When I started out, I would have looked at comments like
"this method assumes that it will only be invoked once"
or
"this only works assuming no more data will be added to this collection"
as "cop-outs" or lazy coding, when in reality they are important design
decisions. Every simplification is the flip-side of an assumption, and
it's better to document (or code!) assumptions directly than leave them
implicit.
A demand-side analysis of AI's impact on the job market
This is the best article I've read since starting this newsletter.
If you click on one link, make it this one.
As people get richer, they don’t just want more commodities. They
want things that aren’t commodities in the standard sense of the
word. The social aspects of products such as the relationships,
the status, and exclusivity—what Rene Girard called the mimetic
properties of desire—become much more relevant once people’s basic
needs are satisfied. And the demand for these properties will
bring the human element back into the production process, and with
it, the jobs.
When AI automates commodity production, prices in that sector
fall. That raises real income. If the goods and services people
want more of as they get richer lie disproportionately in the
relational sector, demand shifts in that direction. Baumol’s cost
disease then amplifies the result: if the relational sector
remains harder to automate, it becomes relatively more expensive
and absorbs a growing share of total expenditure.
I had a discussion this week with co-workers about future AI cost
for consumers. They argued that the model companies aren't
profitable, and that they will inevitably raise prices to recoup
their investments. This is a suspect claim, but apparently popular
among otherwise well-informed people, so I thought I'd address it
here. Two important pieces of information
Holding capability constant, inference cost has fallen 10x-100x
year over year
While providers are operating at net losses, they are profitable
on the margin
Micro 101 tells us that the firms will serve their models at the
point where marginal cost equals marginal revenue. Importantly,
upfront costs don't affect this equilibrium. Even if OpenAI were a
monopoly and faced no competition, so long as the elasticity of
demand is not 0, if marginal costs decrease, part of those savings
will be passed along to consumers.
Being assigned a higher average grade inflating teacher reduces a
student's future test scores, the likelihood of graduating from
high school, college enrollment, and ultimately earnings. ...The
cumulative impact is economically significant: a teacher with one
standard deviation higher average grade inflation reduces the
present discounted value of lifetime earnings of their students by
$213,872 per year.
Related, one proposed solution to grade inflation: capping the number
of A grades awardable, penalizes students for taking difficult
courses.
The real problem is not inflation per se. It’s that students are
penalized for taking harder courses with stronger peers. A grade
cap leaves that distortion intact—and can even amplify it.
...
The underlying issue is informational. A grade tries to capture
two things—student ability and course difficulty—with a single
number. Gans and Kominers show that in general this is impossible:
if some students take math and earn B’s while others take
political science and earn A’s, there is no way, from grades
alone, to tell whether the difference reflects ability or course
difficulty.
Malus provides "clean room as a service" (i.e., the removal of
external dependencies from a software project)
Our proprietary AI robots independently recreate any open source
project from scratch. The result? Legally distinct code with
corporate-friendly licensing. No attribution. No copyleft. No
problems.
This is a consequence of zero-cost software I hadn't considered. An
important question is whether the negative effects of this on the open
source ecosystem will be outweighed by the increase in AI-assisted
contributions. Also raises some interesting legal questions.
https://malus.sh
Robin Hanson's "Grabby Aliens" model (2020) suggests that if humans
stay put on Earth, we won't discover aliens for 500 million years
(median estimate) but once we do, it will only be a few years before
they arrive on our doorstep. Fun idea.
I think this factor is under-estimated when discussing the Fermi
Paradox. If most of the planets in the universe are too far away
for us to see alien life, then if we see it at all we’ll be seeing
their space ships as they come to us. But we won’t even see them
launch to us, even with perfect telescopes staring out into the
galaxy, until they’re almost here. In practice this means that, in
the grand scheme of human history, the phase between becoming
aware of aliens and meeting them is vanishingly short.
The real issue is not “Who will get the profits from AI?”; the
most interesting question is whether AI will lead to the
production of 130 million household servant robots, or the
production of another 2000 mega-yachts. When examining issues of
inequality, it often makes more sense to focus on the structure of
output, not the distribution of income.
...
I often see discussions of AI that makes a similar error, failing
to understand that the essential question is output, not
distribution. Many worriers about AI don’t seem to understand that
these two scenarios are almost identical:
1. What if AI replaces all jobs?
2. What if America becomes so rich that we can all live as
billionaires?
Brain-drain to the U.S. has significantly slowed Canada's economic
growth
From 2014 to 2024, Canada’s real GDP per capita adjusted for
purchasing power parity grew by just 3.2 percent in total, an
anemic 0.4 percent per year on average, and the third lowest among
38 advanced nations. Over the same period, the United States
posted 20.2 percent total growth (1.9 percent annually), and the
OECD average reached 15.3 percent (1.4 percent annually). The
measurement shortcomings cannot explain five-to six-fold
differences in growth rates.
...
The analysis estimates that a substantial share of Canadians who
would rank among top earners in Canada have emigrated to the
United States—roughly 40 percent of potential top 1 percent
earners and 30 to 50 percent of the next nine percentiles.
Canadian-born individuals in the United States are more educated
than native-born Americans, earn substantially more, and cluster
disproportionately in top income deciles.
...
Canada is effectively exporting its inequality to the U.S. The
brain drain simultaneously lowers our average income while raising
American income, accounting for a significant share of the
persistent GDP gap.
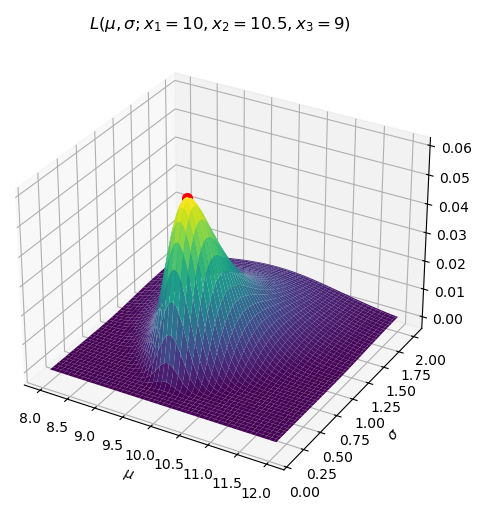
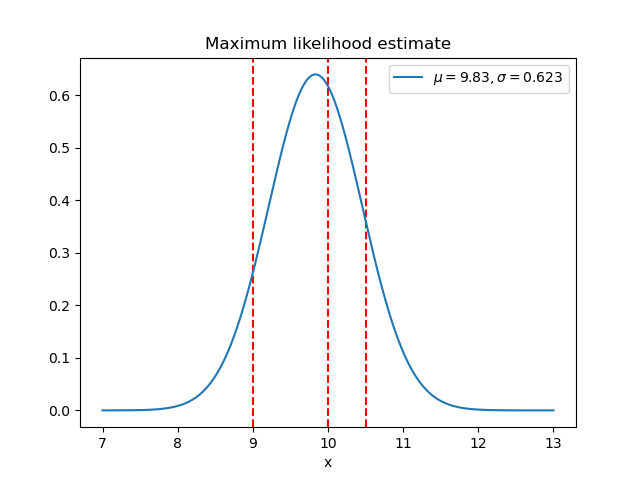
Follows a single example, from Bayesian Inference to a
Kalman Filter
Has visualizations of multiple-dimensions and hidden
variables
Demonstrates the problems Kalman and Histogram filters
encounter
I hope to fill that gap. These notes grew out of a recruiting
talk I gave at UIUC and are intended as a conceptual primer for
one of the theoretical introductions. A familiarity with
calculus, statistics, and linear algebra is useful.
Outline
I’ll follow a single, unifying example: Imagine we’re in a
submarine equipped with active sonar. Like a bat, we can emit a
sound and listen for its echo. Given the echo’s elapsed time and
speed of sound, we can calculate our distance to things.
Unfortunately, we don’t have a perfect knowledge of the speed of
sound underwater, as it varies depending on temperature,
salinity, and depth. We are tasked to find another submarine
which is somewhere nearby. We’ll start with the simplest case:
Both submarines are stationary and we want to estimate only the
distance to the other submarine.
Each act builds on the previous by adding one layer of
complexity. A new technique (and limitations of the old one if
applicable) will be discussed at each stage
Act
Added complexity
Topic
1
Single measurement, stationary
submarine (Baseline)
Bayesian Inference
2
Multiple measurements
Recursive Bayesian Inference
3
Moving submarine
Kalman Filter
4
Non-Gaussian prior
Histogram Filter
5
Tracking more dimensions than
range (e.g., lat, lon)
Particle Filter
Act 0 provides a recap of Bayes’ rule. Act 6 describes
resampling and perturbations: two heuristics for better
performance with less computation.
Act 0: Math Recap
The easiest way to remind yourself of Bayes’ theorem is to
re-arrange the law of conditional probability (the comma means
“and”, and the bar means “given”):
Bayesian inference is a technique which repeatedly uses
Bayes’ theorem to understand some outcome/event of interest
as we observe
events/collect data which tells us something about it . For example,
“given that a card is red, what is the probability it is a
heart?”
is called the prior.
This is the initial degree of belief in the hypothesis .
is called the
posterior. It is the degree of belief in after incorporating the news of
.
is the likelihood.
It is the probability of the data given the hypothesis
is called the
evidence, or marginal likelihood. It is the probability of the
data under all hypotheses.
The crux of Bayesian inference is that once we have , if we observe another event,
(which is independent of
) we can “update” our belief
about by making our prior and starting again
to find a new posterior, . Note that we don’t have to
start from scratch each time we get additional evidence, only
compute Bayes’ theorem one more time. All of our knowledge thus
far about is contained in the
posterior.
What do I mean by “degree of belief”? If you haven’t come
across the distinction between Frequentest and Bayesian
statistics, a frequentest will take a weighted coin, and will
say “flip it 1 million times, and the ratio of
is the probability it lands heads. A Bayesian will take a
weighted coin and say probability is the”degree of belief” I
hold that it will land heads. i.e., if I had to place a bet on
it, what “probability” would make for a fair betting line?
We can derive Bayes’ theorem for probability density
functions similarly:
Remember the evidence, , is the probability density of
the data under all hypothesis (possible values of ). In the continuous case you would
write this as an integral
Act 1:
One Measurement of A Stationary Submarine
To our submarine example, let’s make the following
simplifications:
The problem is one-dimensional
Both submarines are stationary
The sonar readings are centered on the true distance with
some noise. To be precise, they follow the normal distribution
with ,
and . A positive
value means the object is in front, negative means it is
behind.
🛥️ ········)) 🛥️
<───┼───────────────────┼───> x
0 ❓
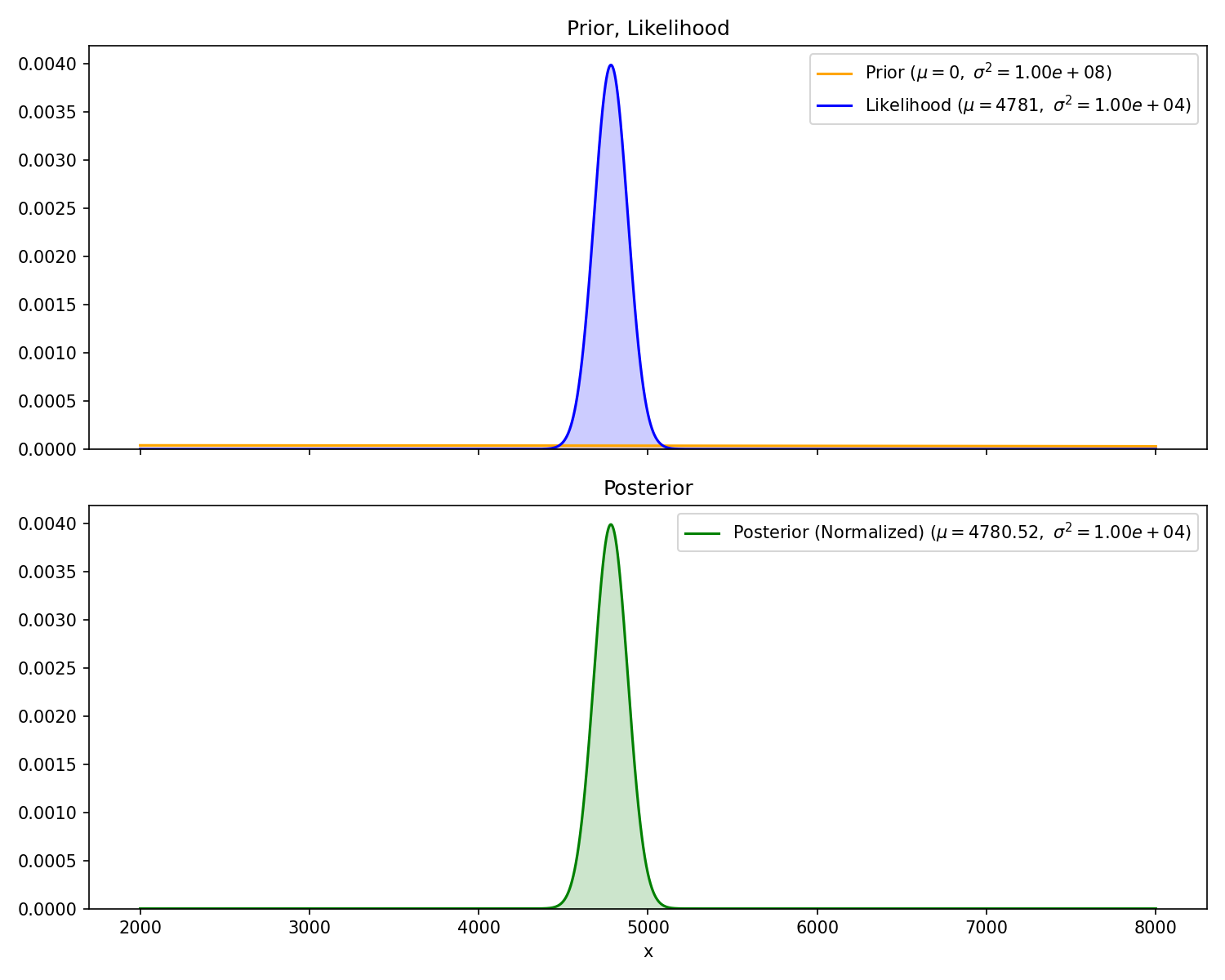
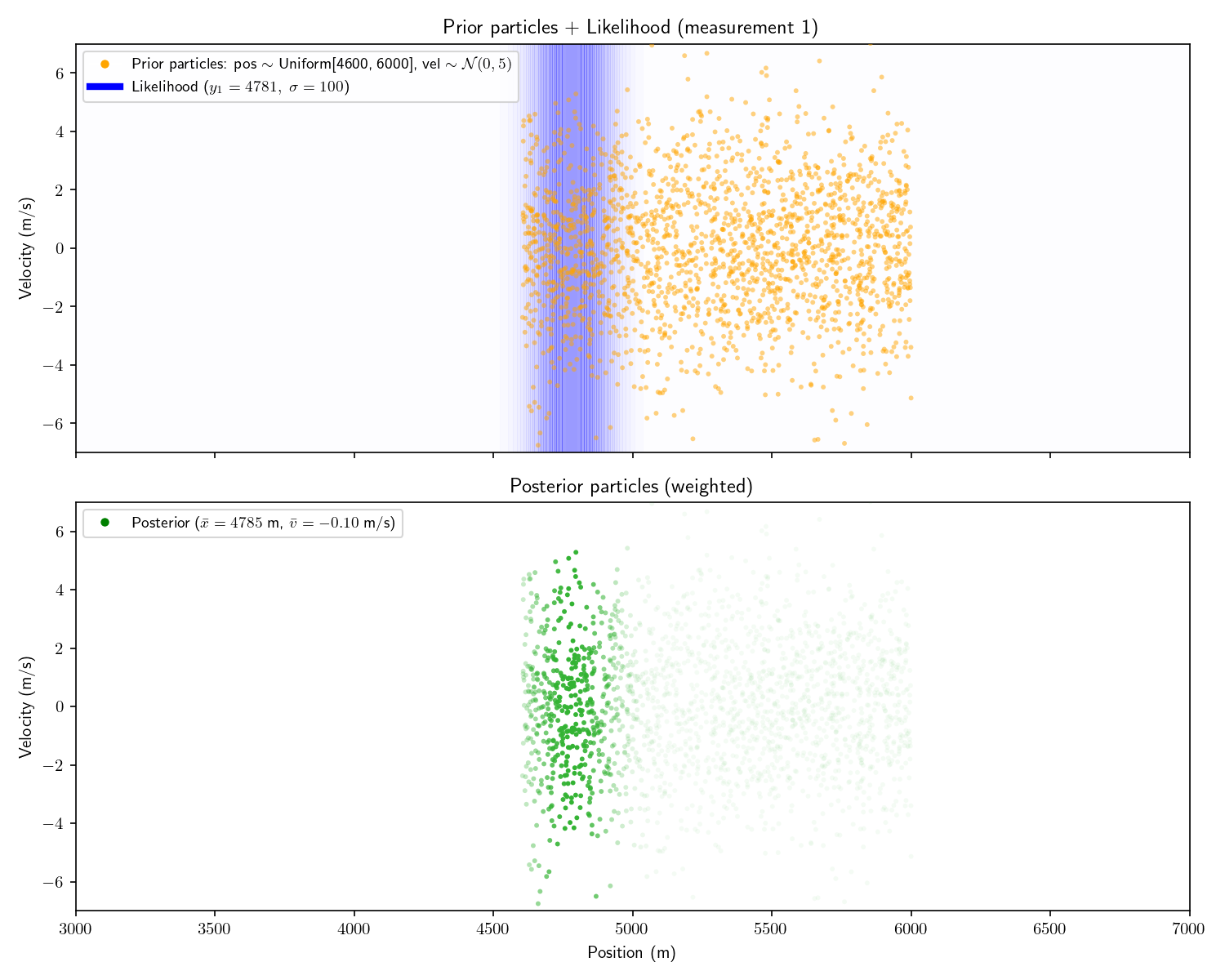
Given the following measurement
Measurement
Range
#1
4781 meters
what is the probability distribution of position of the other
sub? Let’s approach this as a Bayesian. Call the distance to the
other submarine and the sonar
reading . Here’s Bayes’
theorem again:
Here, represents the
“state” of the other submarine (also called our “hypothesis”)
and represents the
Evidence/Data we have about this state. The core problem is that
we have a probability density over possible observations, , but we want a pdf over state,
. Bayes’ theorem is what
achieves this.
We need two things to calculate our posterior. First, the
prior . This represents
our belief about the other sub’s position before receiving any
measurement. Since we don’t have any a-priori knowledge, we can
use a Gaussian distribution with extremely high variance (i.e.,
very flat) which loosely says “it could be anywhere”.
Aside: however wide, this prior is not uniform: it has
slightly more probability around 0 than at 1000m. We can’t make
our prior’s variance infinite as that is ill defined, but we
could have used an uninformative, improper prior.
“Uninformative” meaning it contains no information (uniform
everywhere) and “improper” because it doesn’t integrate to 1.
While I won’t go into more detail here, I point it out because
sometimes people say you can “initialize the particle filter
using the first measurement” (i.e., use the normalized
likelihood function of the first measurement as your prior), but
really what they’re doing is applying Bayes’ rule with an
uninformative prior.
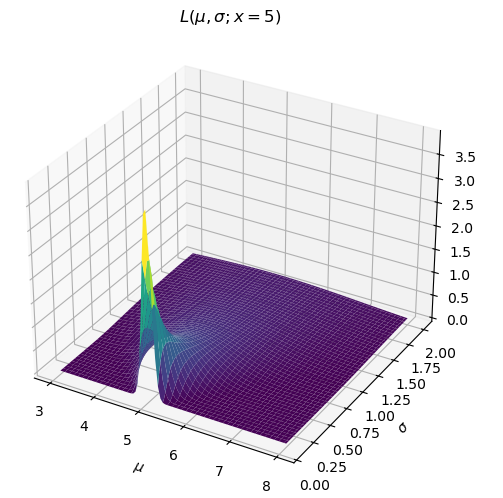
Second, we need our likelihood function, . This is defined as the
probability of measuring
given the state, . The problem
statement directly gives this to us: “The sonar readings are
centered on the true distance with standard deviation of 100”.
Here, the “true distance” is
Now, we can plug these into Bayes’ theorem and solve for the
posterior .
Fortunately, the product of two Gaussian Distributions is also
Gaussian (proof)
with mean and variance
The denominator (evidence), , is a scalar value (remember,
is given). Therefore, the
posterior is also a Gaussian. I won’t go through the entire
derivation here, but understand the solution is analytical
Aside: an analytical solution is derived by moving around
variables with pencil and paper (e.g., anything you did in a
high school algebra class). It is exact. Numerical solutions, on
the other hand, are calculated via an algorithm and are
approximate. They typically incur some discretization or
rounding error which approaches zero in the limit of infinite
memory or compute time.
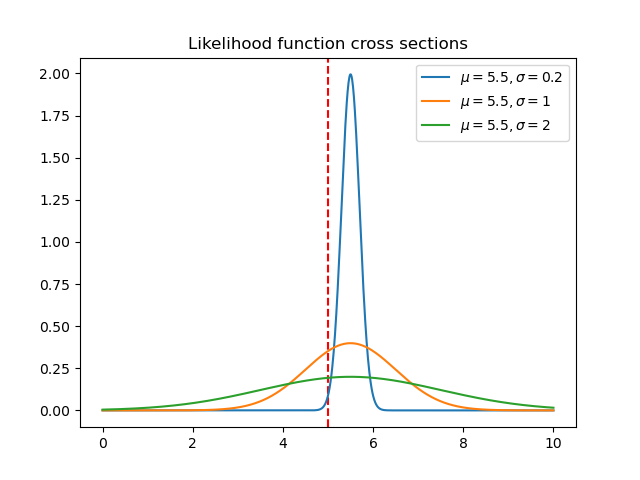
I’ll note a few things. First, the prior is hard to see
because it is pretty close to a flat line right around 0.
Second, the mean of the posterior is very slightly less than the
measurement. This is because our prior is centered at zero, so
it will still “pull” the posterior towards it, no matter how
flat it is. Third, the equation for the standard deviation,
, above guarantees that
the variance of the posterior is less than or equal to the
variance of prior and likelihood Gaussians.
Act
2: Multiple Measurements of A Stationary Submarine
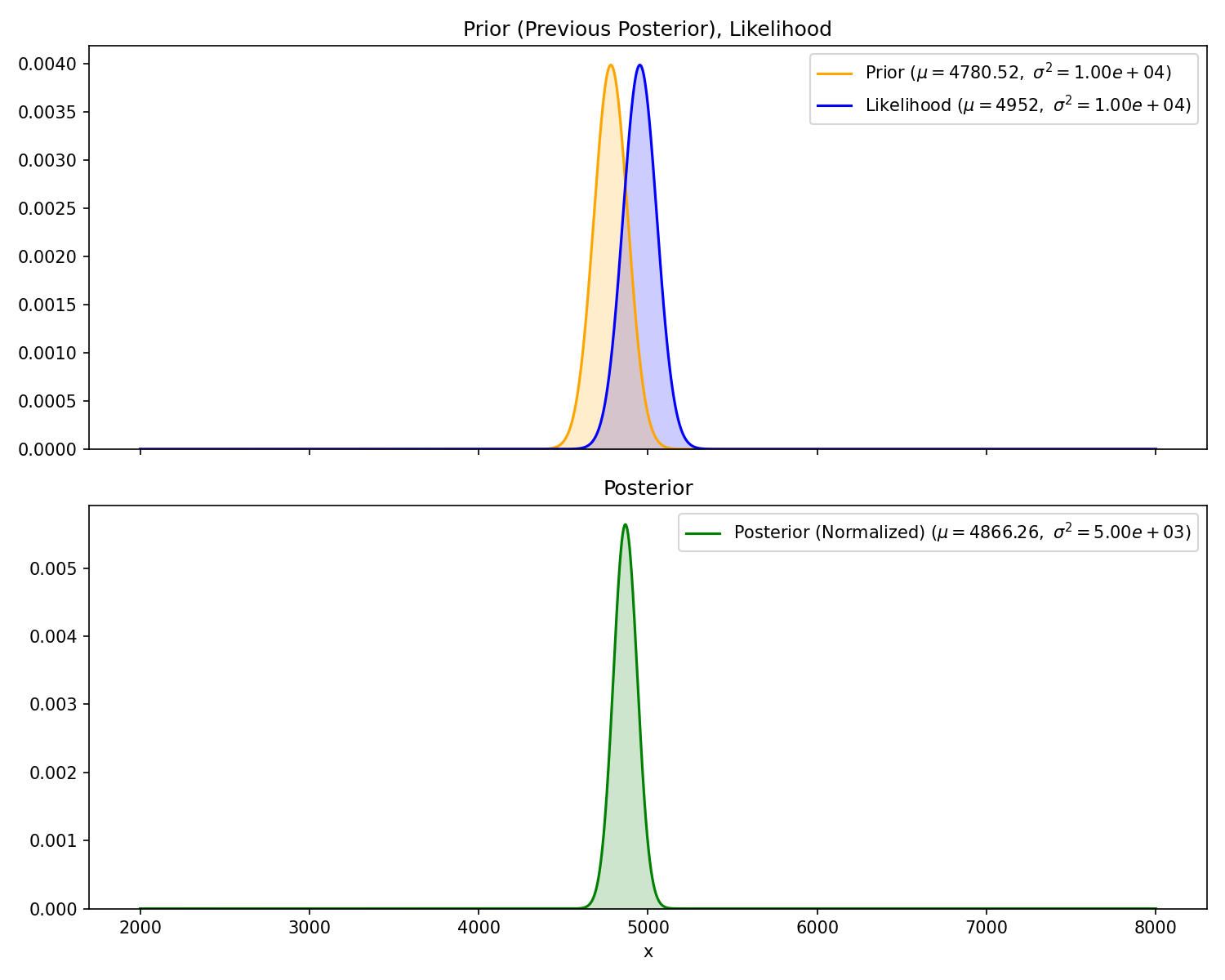
Now, we get a second measurement,
🛥️ ···))·····)) 🛥️
<───┼───────────────────┼───> x
0 ❓
Measurement
Range
#2
4952 meters
And we’d like to update our probability distribution of the
other submarine’s position, . Recalling the math recap from
the beginning, we can use the posterior from Act 1 as our new
prior, rinse and repeat.
Again, the variance of the posterior is smaller than the two
inputs. Since the variance of the prior and likelihood are
roughly the same, the mean of the posterior is half way in
between the two.
One of the powers of Bayesian inference is that it allows
subjective priors. By that, I mean your domain knowledge and
lived experience may give you a hunch that the other sub likes
to hang out in some area and is therefore probably some distance
away. Bayesian inference allows you to turn this “hunch” into a
prior. This is possible because (in theory) no matter what prior
you choose (so long as it is not zero where it matters) with
enough measurement updates eventually your posterior will
converge on the true distribution. Therefore we can leverage
subjective “hunches” while maintaining some mathematical
guarantees.
Act
3: Multiple Measurements of a Moving Submarine
Now, the other submarine is moving, but we don’t know how
fast. We take sequential sensor measurements. Our goal is to
estimate (at the time of the last measurement) the velocity and
range of the other submarine. We’ll make the following
assumptions
🛥️ ···))······)) 🛥️💨
<───┼───────────────────┼───> x
0 ❓
Everything is still in one dimension
The other sub is moving at a constant velocity
Our prior on the other submarine’s velocity is where a negative value means it is getting
closer.
The state of the other submarine is now a random vector :
And its probability distribution is now multivariate Gaussian
.
Our prior is
Again, we will employ Bayesian inference. The problem is now
two dimensions, but conceptually the technique is the same. We
will treat the first measurement just as we did in Act 2.
However, after calculating the posterior of the random vector, instead
of immediately turning it into our next prior, we first must
update it with time. To do this, we need something called a
“motion model” or “state update equation”. Given a state at
, and our assumption of
constant velocity, the state at is given by
where is the time
in between each sensor reading. This is a linear transformation
we can write in matrix form:
(I’m sticking with convention here to call this matrix ).
Given a state vector we can transform it with time, but how
do we transform a continuous distribution? Let’s change our
framing slightly; instead of thinking about probability
distributions, let’s consider the random variable which
this distribution describes. Again, we are fortunate that our
variable is Gaussian. Thinking back to an intro stats class, you
may remember that multiplying a random variable by a constant
scales its mean by and its variance by . This extends to random vectors.
Given any linear transformation ,
Because the Gaussian distribution is defined by this mean and
variance, the resulting distribution of our random variable is
also Gaussian with
So long as our motion model is a linear transformation and
our prior and measurements are still Gaussian, the posterior
will remain Gaussian, and therefore the entire process can be
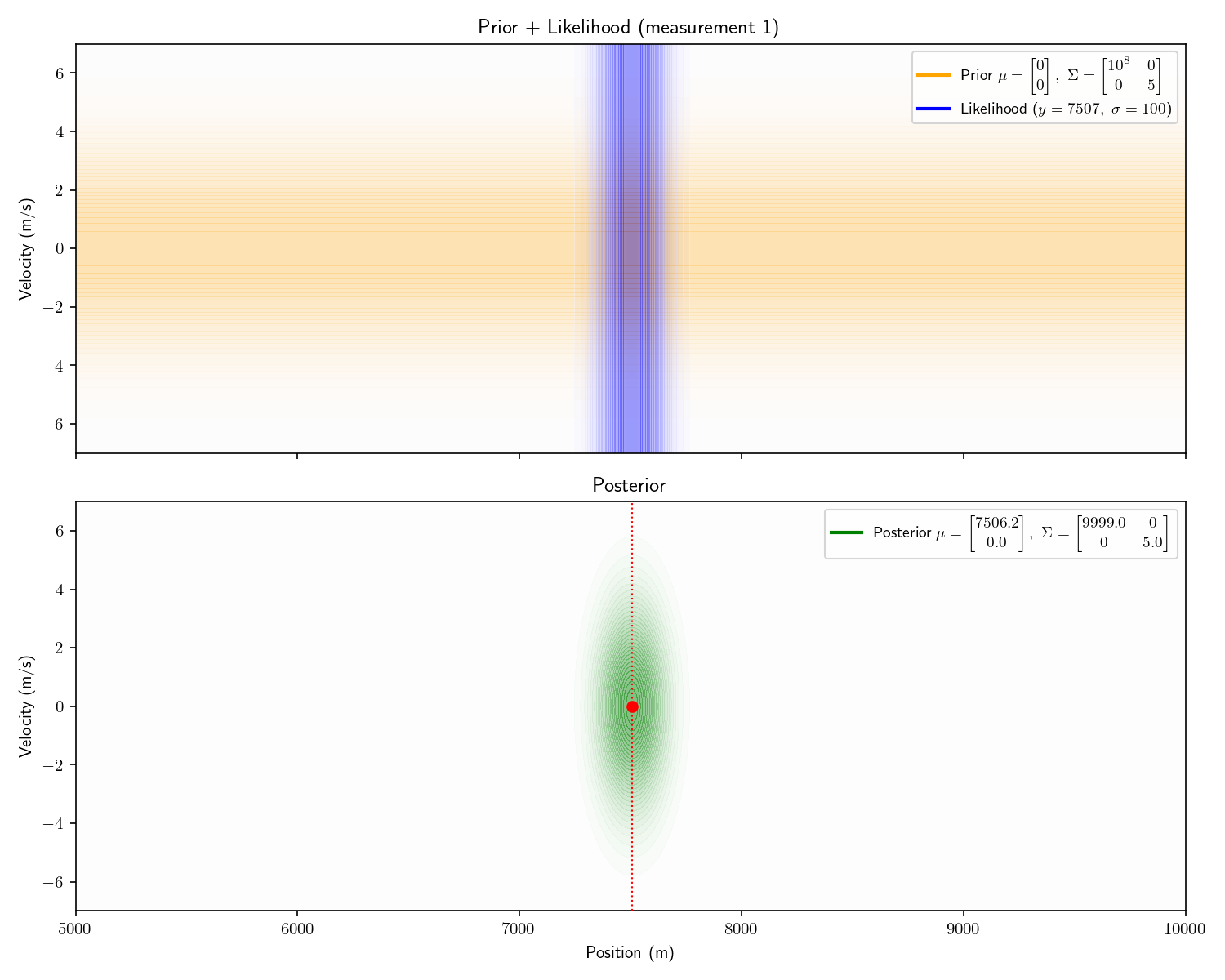
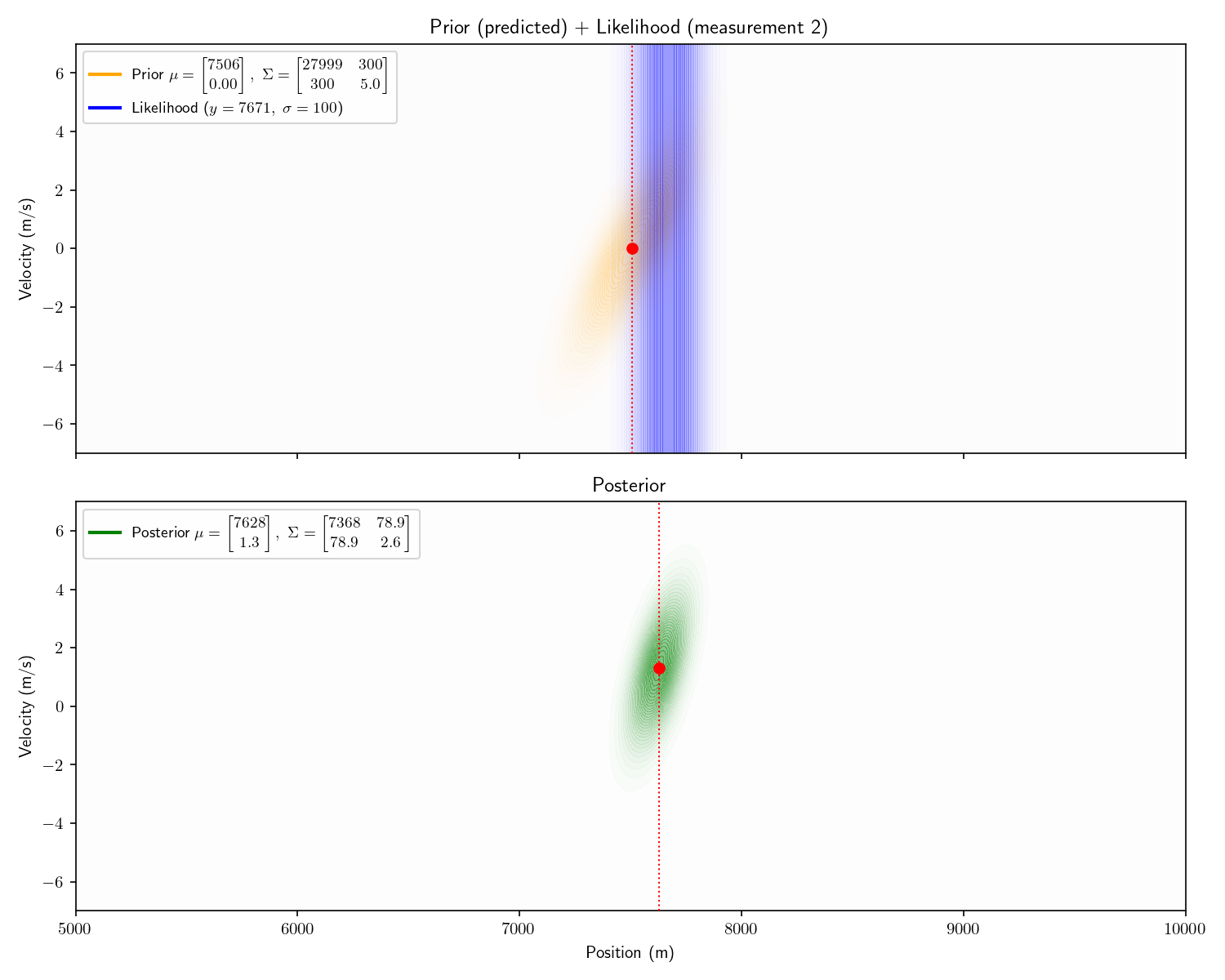
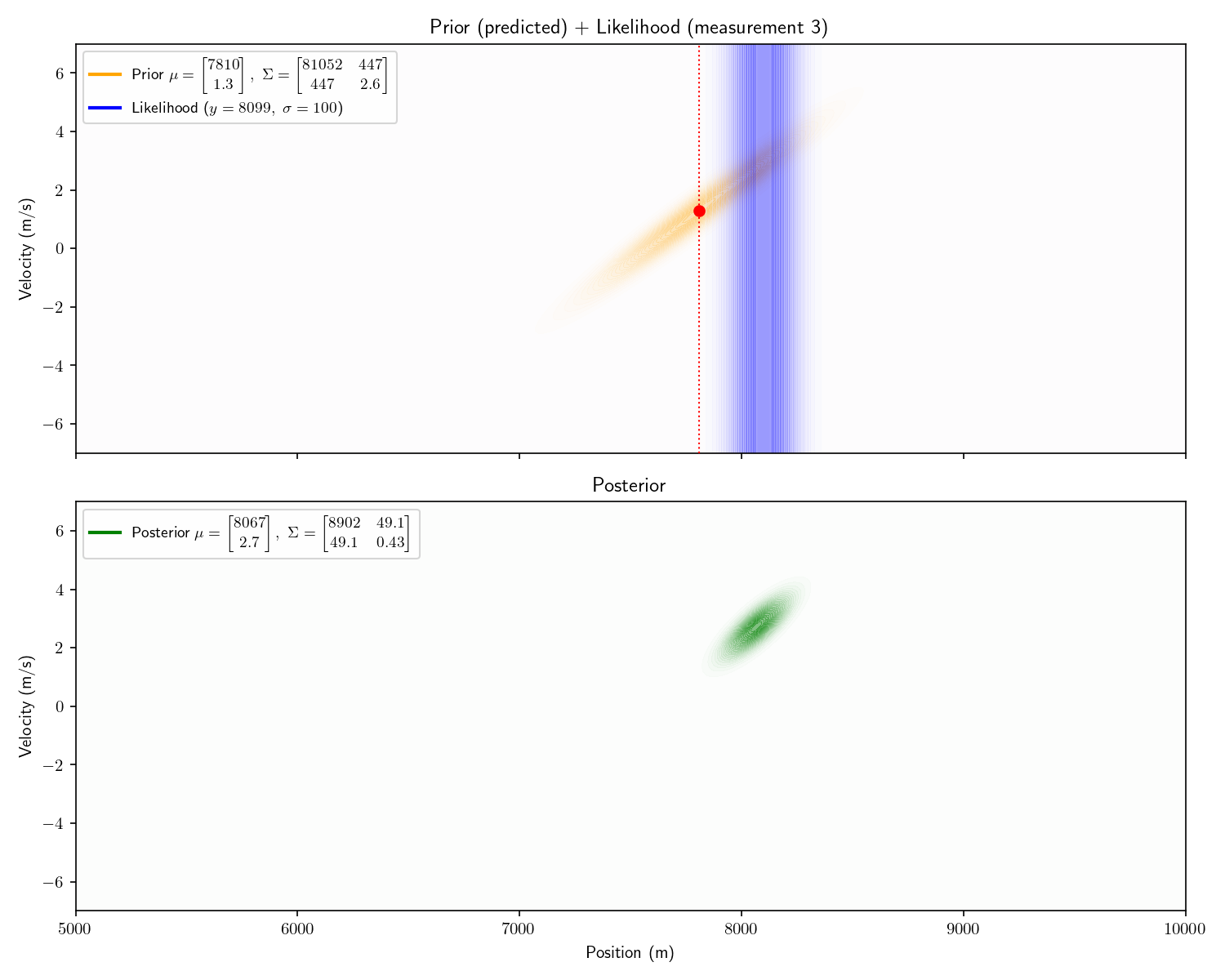
solved analytically. Say we receive the following three
measurements:
Measurement
Time
Range
#1
0 seconds
7507 meters
#2
60 seconds
7671 meters
#3
200 seconds
8099 meters
To process the first, we apply Bayes’ theorem just as we did
in Act 2. I’ve plotted top-down heatmaps of our probability
distributions. Getting oriented, an informationless prior would
look like a uniform, light orange background. Our prior is a bit
better than informationless: we know the velocity is probably
between m/s.
Our sensor still provides only range information. Therefore
it appears as a 1D Gaussian smeared uniformly across the
velocity axis.
Aside: I haven’t plotted the actual prior here – it would
appear as a single color. I’ve emphasized things for visual
effect.
Notice how the posterior mean is slightly lower than 7507.
This is because our prior is not truly “informationless” it is
just a very flat Gaussian centered at 0, so it will pull the
posterior slightly towards 0.
Aside: the first posterior’s covariance matrix has 0s in its
off diagonals. This is a fancy way of pointing out that it isn’t
slanted. After we apply the motion model, these off-diagonal
elements become non-zero and it becomes slanted. It is this
covariance matrix that carries the “information” about the
relationship between the possible positions and velocities:
i.e., “If the sub has a positive velocity it is probably further
away now”.
Let’s zoom out for one moment. Our goal is to motivate the
particle filter. Until this point we haven’t defined
“particle” or “filter”. The approach I’ve just
described is is called “recursive Bayesian estimation”
or a “Bayesian Filter”. The first phrase describes
exactly what we’ve done: recursively apply Bayes’ theorem to
estimate the state of the submarine. As for the latter,
“filtering” simply means we are estimating the state of
the submarine at the time of the last measurement as opposed to
during the whole encounter. At this point you know literally 1/2
of “particle filter”, and our conceptual understanding
is roughly half way there as well.
In particular, a Bayesian filter where the prior and
measurements are Gaussian and the state update is linear is
called a “Kalman Filter”.
Notice one more thing about our results. Our final posterior
tells us that the other submarine’s velocity is between +2 and
+4. This is remarkable because we never received any information
about its velocity! We call velocity a “hidden state” because it
is never observed. One powerful trait of Kalman Filters is that
they can provide estimates of states which are never
observed.
Aside: the Kalman filter can also represent Gaussian
noise in the state update. For example, imagine the velocity of
the submarine depended on the temperature/salinity of the water.
We could model the effect of this unknown environment as
Gaussian noise (just like we did with the
measurements).
Aside: the “extended Kalman filter” (EKF) can use any
differentiable function for the state-transition model (rather
than linear). This involves constructing a Jacobian (matrix of
partial derivatives) to update the covariance with. The EKF is
the de facto technique of GPS systems.
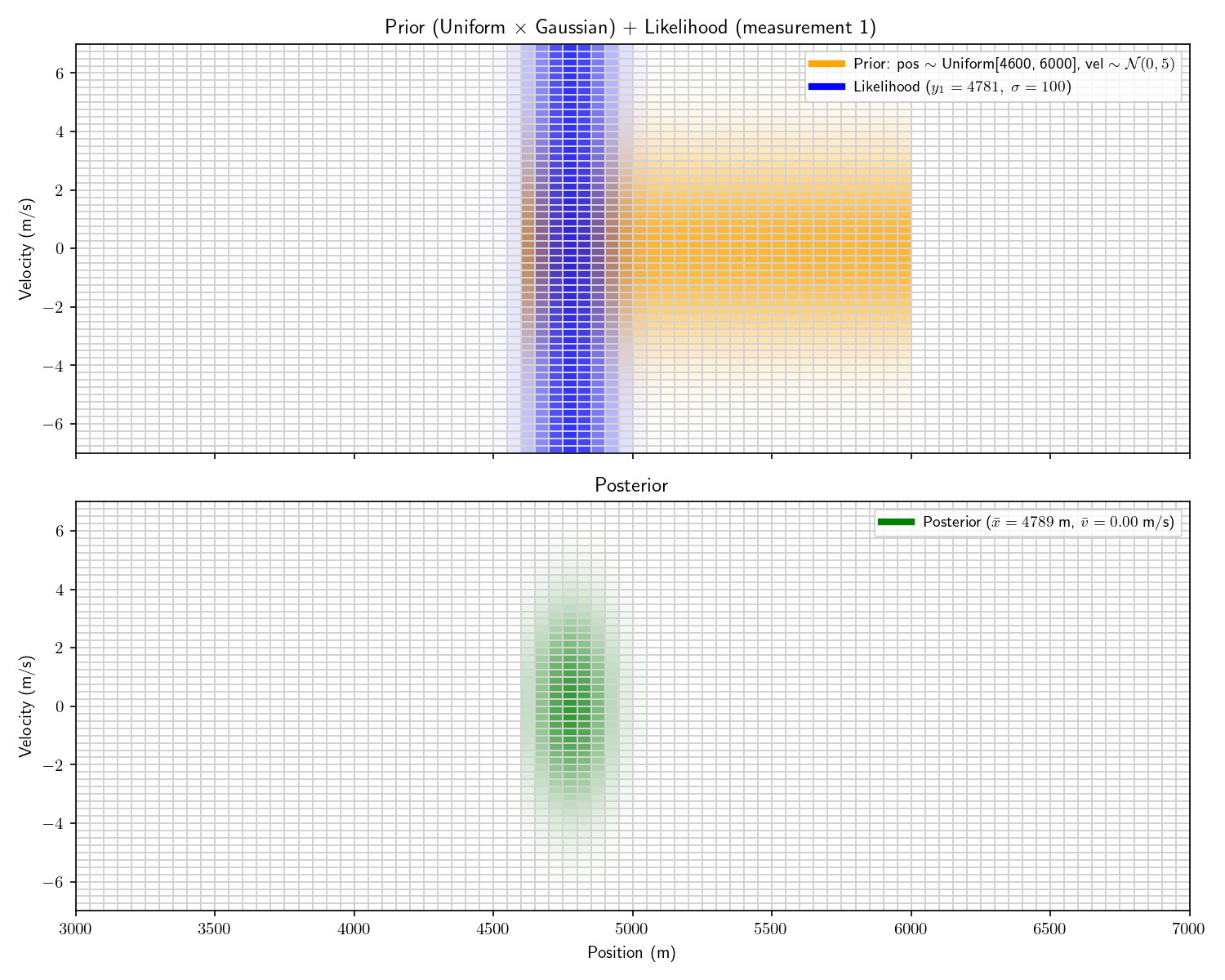
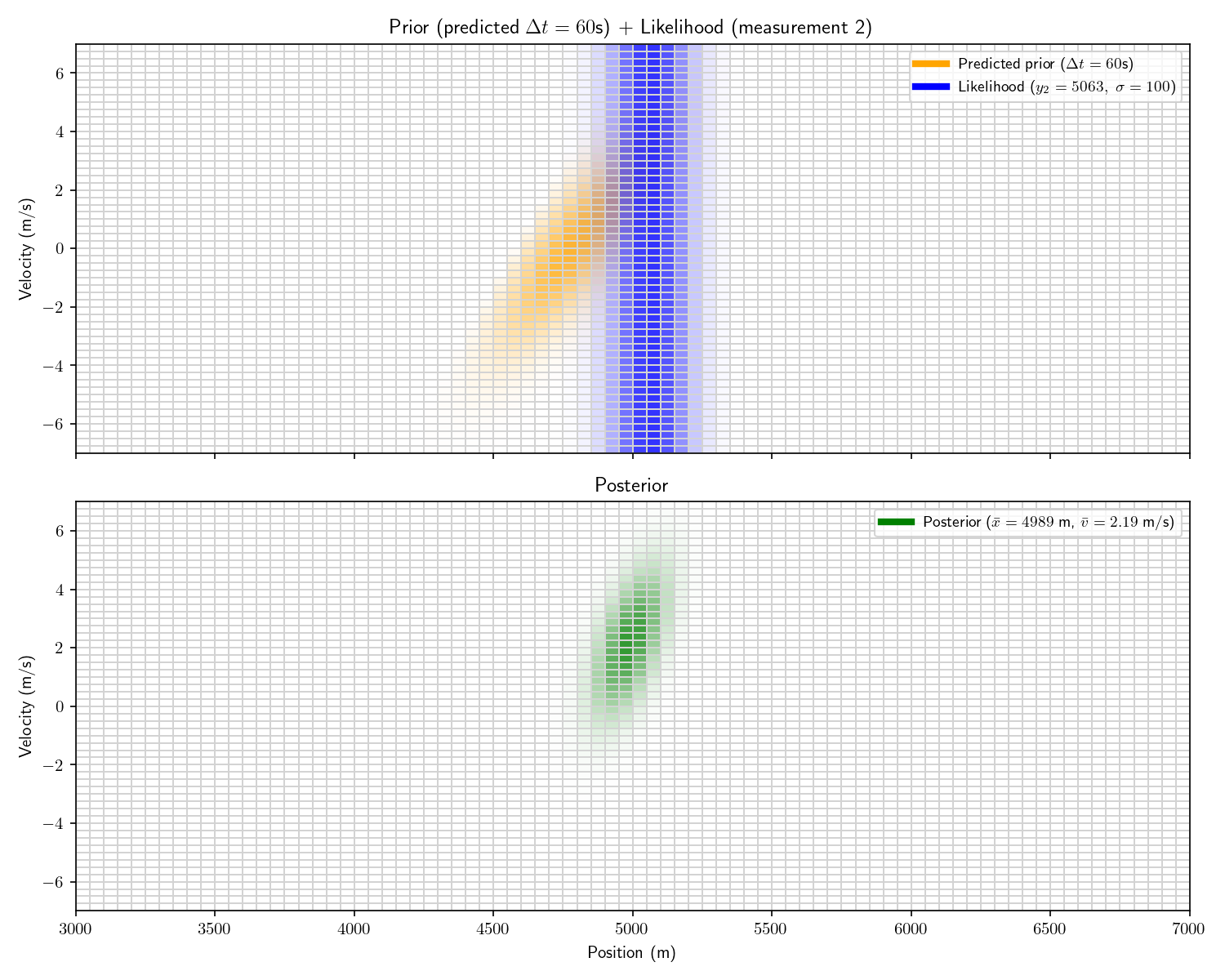
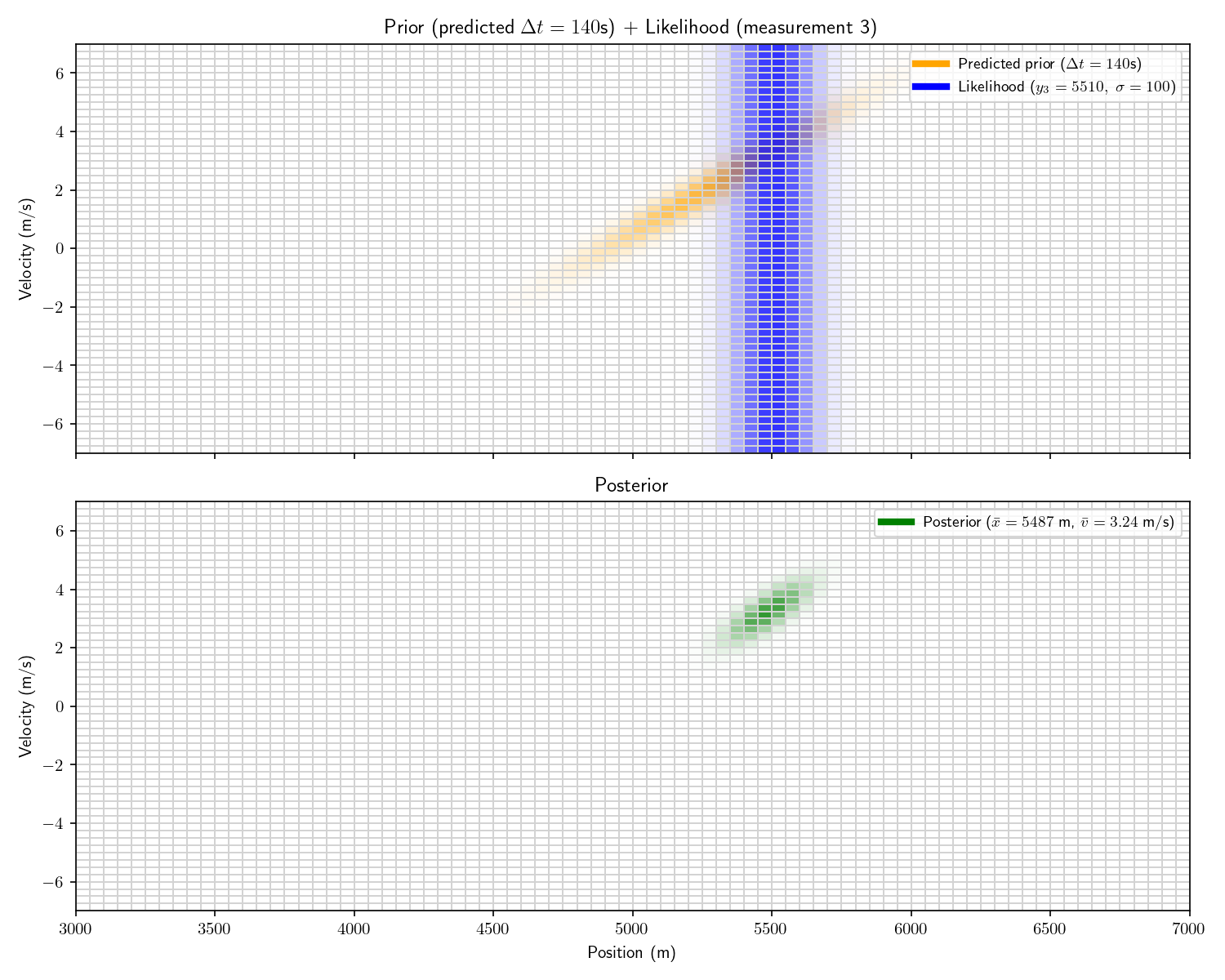
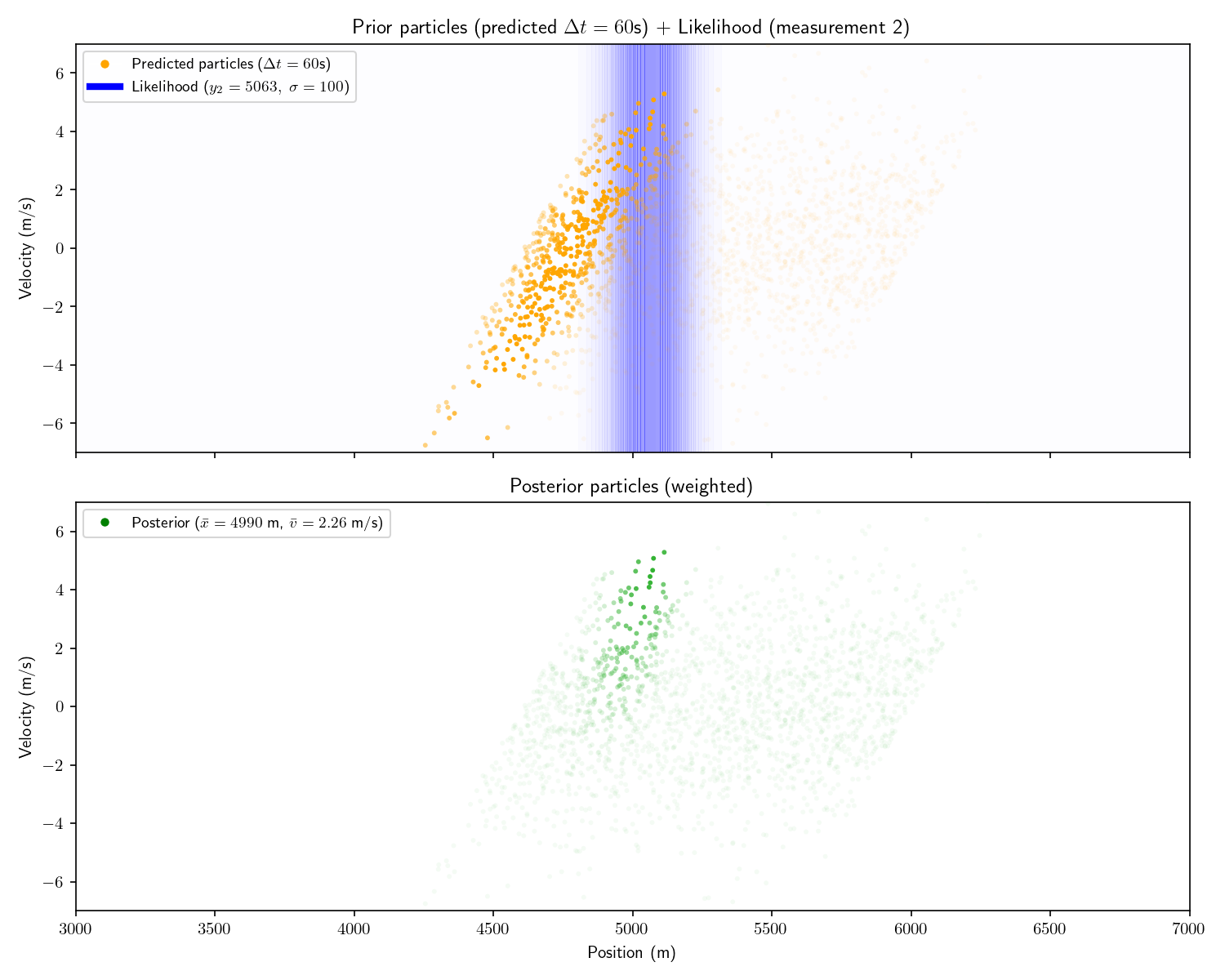
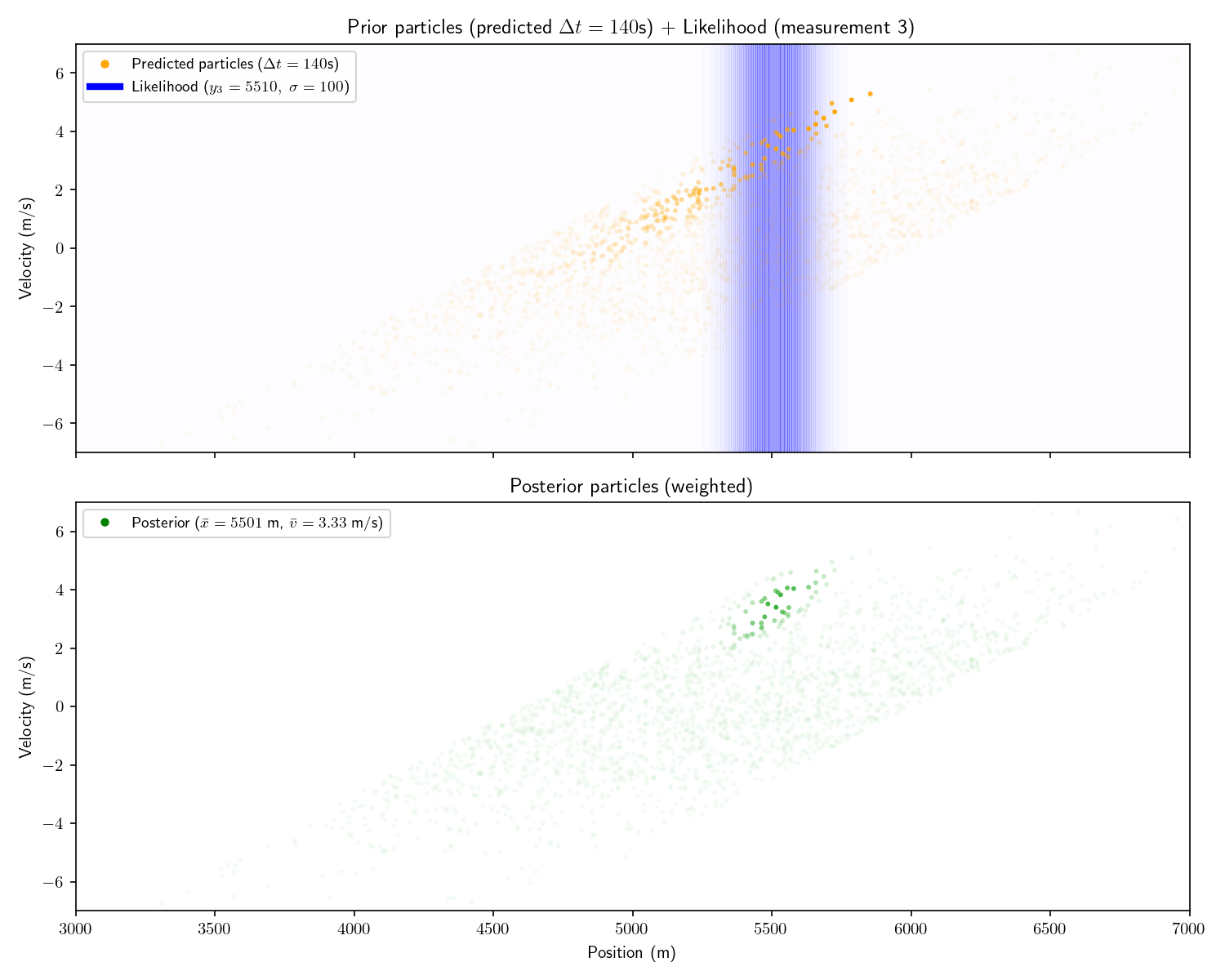
Act 4: Histogram Filter
Now imagine that before receiving the first sensor report, we
receive an intelligence that the other submarine is between
4,600 and 6,000 meters away.
🛥️ ···))······)) 🛥️
<───┼────────────────┼──────────┼───> x
0 4,600 ❓ 6,000
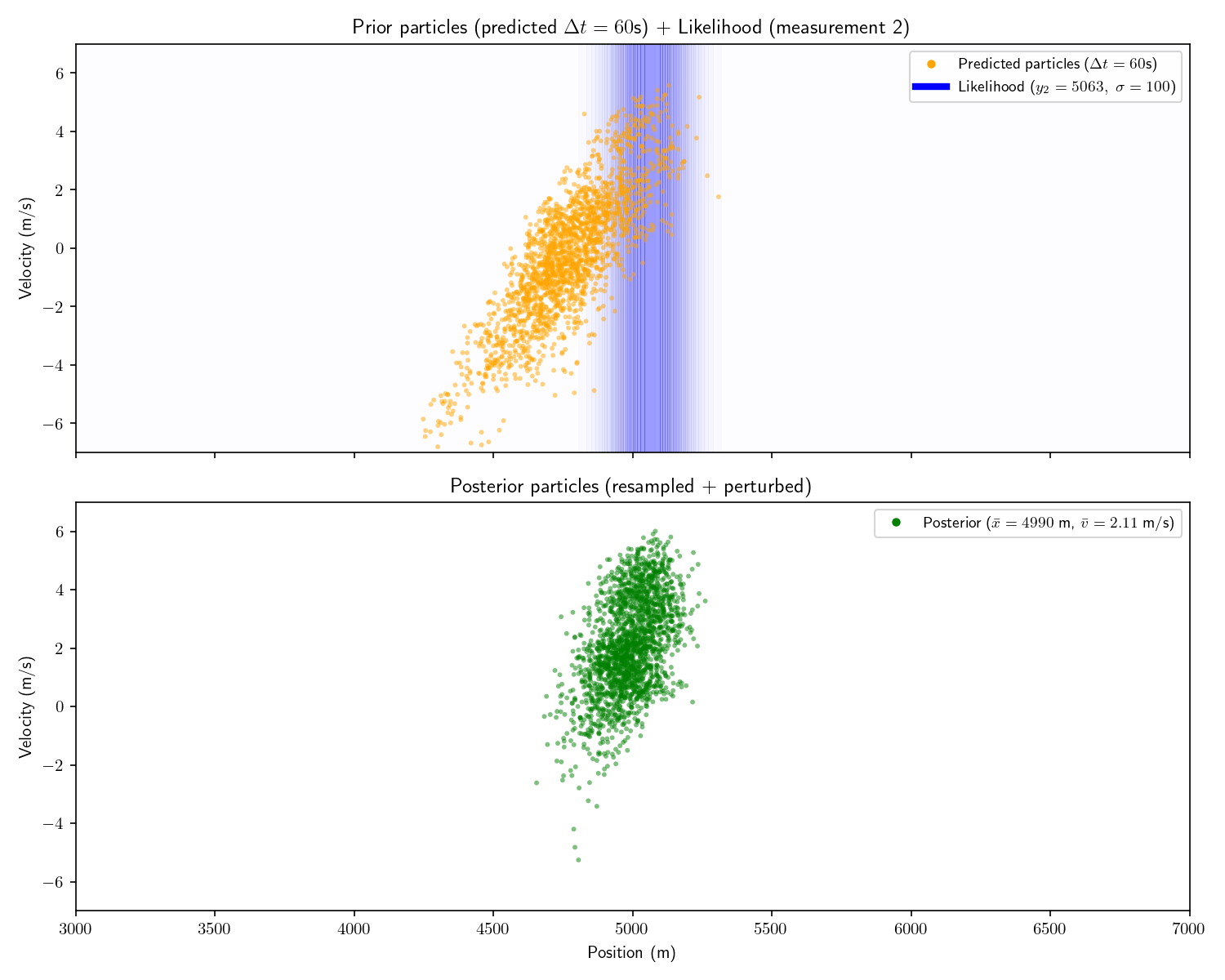
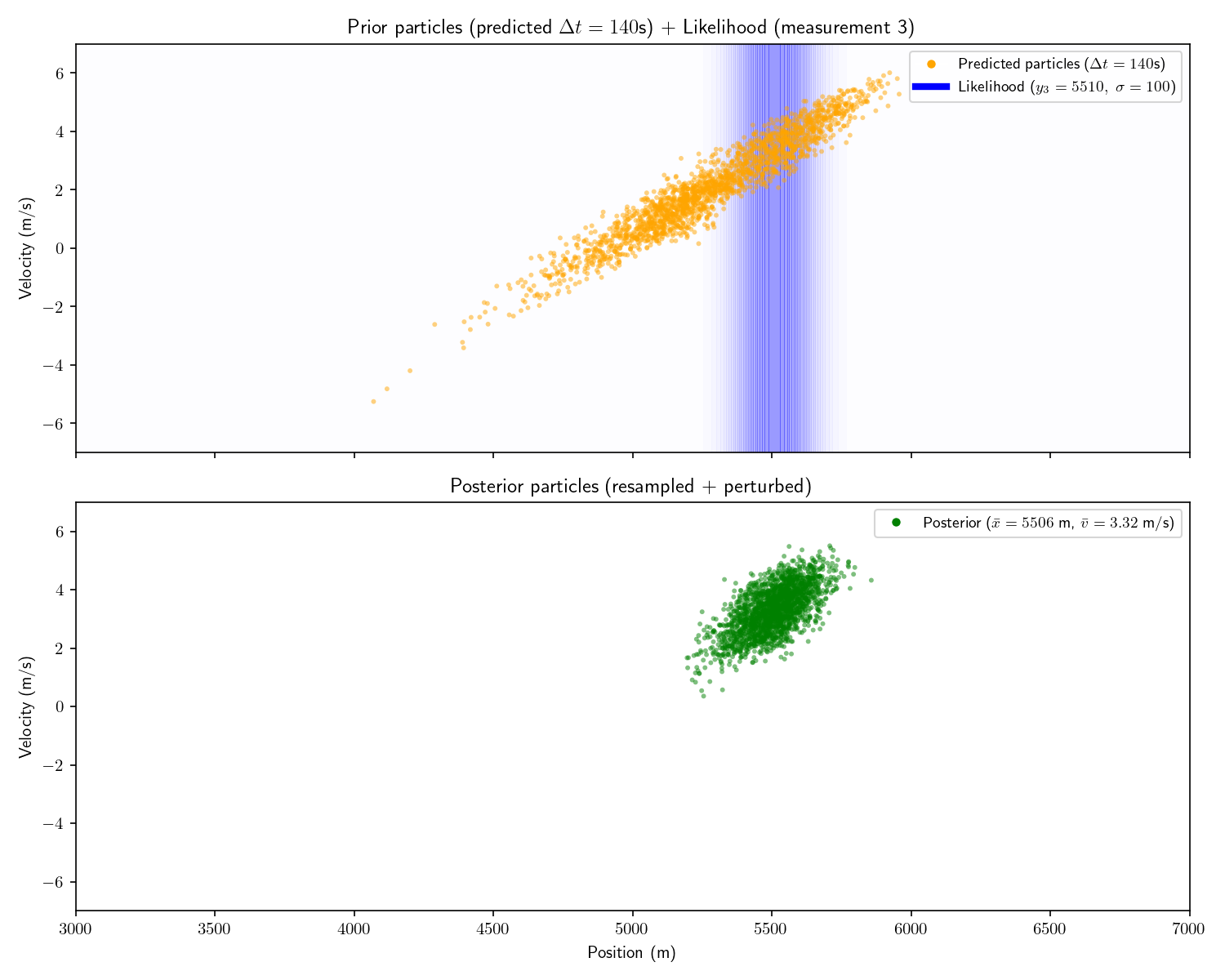
And then we receive the following three measurements:
Measurement
Time
Range
#1
0 seconds
4781 meters
#2
60 seconds
5063 meters
#3
200 seconds
5510 meters
We can incorporate the intelligence report into our Bayesian
framework as a uniform prior:
The problem with a uniform prior is that we can no longer
solve the problem analytically. What can we do instead? One
option divide the x-dimension into 200 “bins” then calculate the
prior and likelihood for each bin. Then, using the same linear
motion update
For each bin in step ’s
posterior, transform its state into using and add that probability to step
’s prior’s bin at .
Aside: alternatively we could have used a Gaussian prior
with (, called it close enough, and used a Kalman
Filter. This sounds hacky, but it’s often often a good
option.
Let’s take one more step back. What we’ve just constructed is
called a “Histogram Filter”. Our solution is no longer
analytical – that is we’ve approximated our continuous
distributions with a finite grid. This sacrifices some
precision, but allows us to consider non-Gaussian priors.
In this Act we used the same motion model as in Act 3. However, now that
we’ve abandoned the requirement of an analytical solution, our
motion model no longer needs to be linear either. So long as we
can come up with a way to “update” the probability in the
posterior forward in time, we can do so however we wish. For
example, say we know that every 10 minutes the other submarine
turns around. We could have a literal if-else statement in our
motion update that if , negate the velocity.
This is impossible with a Kalman Filter.
Finally, note that while our measurements have remained
Gaussian they need not have. Once we start solving things
numerically, we can drop any requirements about functions being
Gaussian.
Act 5: Particle Filter
Now let’s consider a higher-dimensional problem: both
submarines move in three dimensions. We would like to track both
position and velocity
. Assume our
measurements are 3d Gaussians on and our prior is a uniform
distribution over a cube in .
If, like before, we split each dimension into 200 bins, we
now have bins. Using
one float (32 bits) to store each bin’s value would require
. This is an
example of “the curse of dimensionality”.
Let’s think about what’s happening here. In our 2-dimensional
example, after 3 measurements we are almost certain the other
submarine has a positive velocity. We nonetheless multiply the
prior (0) by the likelihood (0) to get the posterior (0) for
every bin with negative velocity. This is a tremendous waste of
compute. There are some tricks like having a dynamic
discretization: have very wide bins where there is no
probability and very small grids where the probability is
non-zero. Possible, but adds quite a bit of complexity.
Note that the Kalman filter does not suffer from the curse of
dimensionality. Since it only needs to keep track of the mean
and covariance matrix, which, in 6 dimensions only require 42
floats.
Aside: the idea of assuming a Gaussian distribution to
avoid the curse of dimensionality is not unique to the Kalman
Filter. In machine learning, Quadratic Discriminant Analysis and
Naive Bayes leverage this idea.
The particle filter solves this problem. Instead of moving
our probability between bins, leaving many bins with zero
probability, why not move the bins themselves? Call
these moving bins “particles”. Each particle is comprised of its
state
and its probability which we call its “weight”.
To construct our set of particles, sample from the first
prior distribution. There is no longer a need to discretize our
likelihood functions as we can evaluate them directly at the
state of each particle. After applying the likelihood function,
we update each particle using our state-transition model . Like the histogram filter, we need
not use a linear state-transition model or Gaussian
prior/likelihoods. Note that the superscripts denote the
particle index, not an exponent. Typically, the subscript is
reserved for the time index.
At each step the prior is the set of original particles and
their weights and the posterior is the set of particles with
updated weights. Each particle’s weight is updated according to
Bayes’ theorem.
I’ve written “”
(proportional to) instead of “” because there is one more step to
calculate the new weight. The particles comprise a probability
distribution, so the sum of their weights should sum to 1.
Therefore, we divide each weight by their sum. The effect of
this normalization is the same regardless of any constant
factor, so we can ignore the evidence constant.
Aside: people often get lazy and say “the particle’s
likelihood”. This is short for “the likelihood of the
measurement conditioned on the particle’s state”. Particles
don’t have likelihoods.
For consistency, I’ll show the same 2D example as from Act 5.
It’s important to understand that this technique can scale to
higher dimensions, but things are simpler to visualize in
2D.
Note that in these plots I’ve set a floor on the opacity of
each particle to help visualize things. Had I let the opacity go
to zero, the very opaque particles would all disappear.
I’ll pause here and say that a particle filter with infinite
particles and a histogram filter with infinite bins, will
converge on the same analytical posterior provided by a Kalman
filter. Of course, we’re doing all this to avoid trillions of
cells let alone infinite ones, but it’s good to know things will
converge to the correct answer. Everything from here on is a
trick to use less compute, not a mathematical requirement.
Aside: what I’ve described here is called a “bootstrap
filter”. It is a particular kind of particle filter where
certain assumptions are made so that . This isn’t
always the case. I’ve omitted the mathematical details since I
don’t think they are necessary for a conceptual understanding.
You can read more on Wikepdiahere.
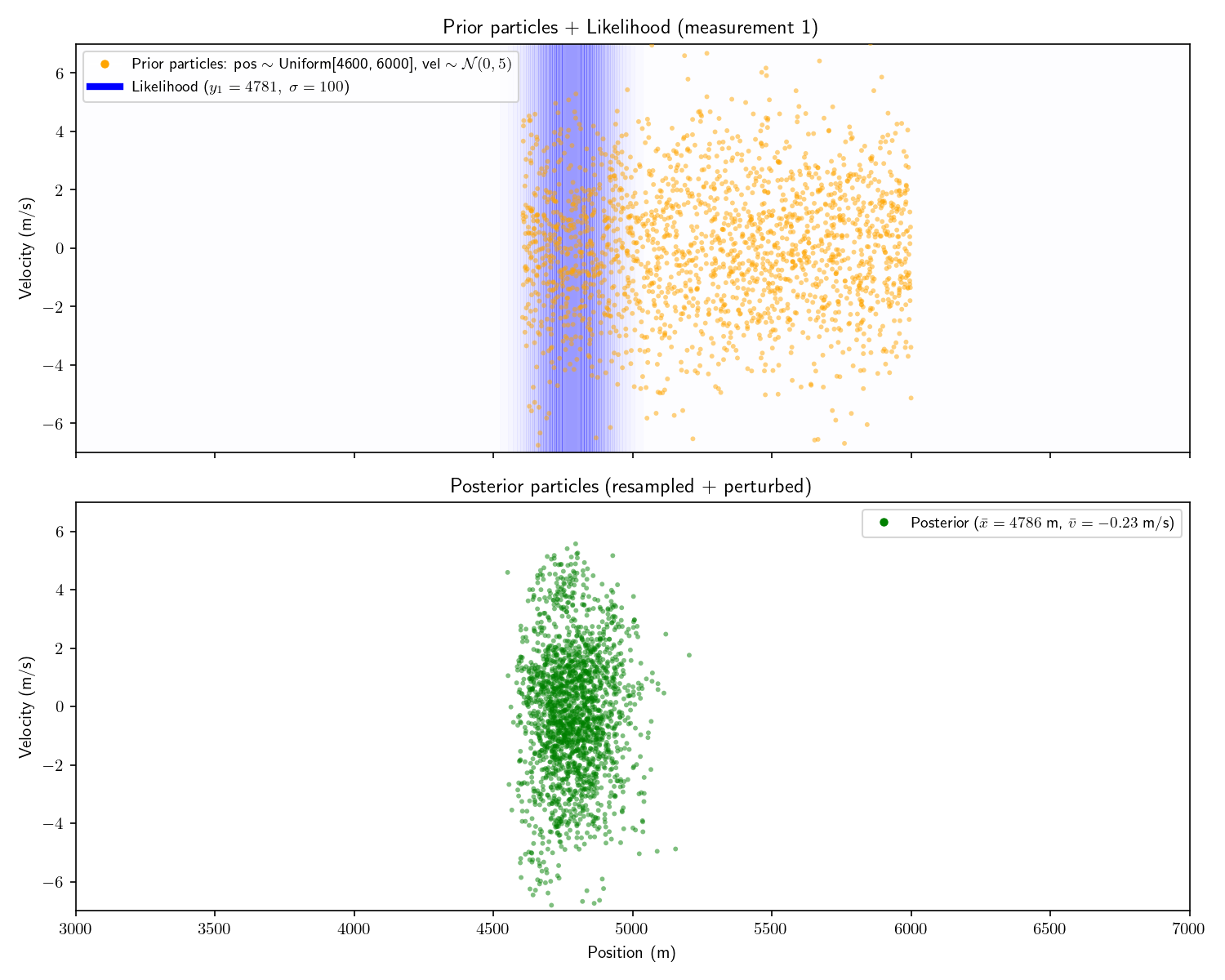
Act 6: Resampling
and Perturbations
My critique of the histogram filter was that it wasted effort
computing bins which had zero probability. We could make the
same critique here: most of the particles have near-zero weight
but we keep them around.
The solution is to “resample” the particles. Imagine we have
100 particles. Originally each has weight . After performing the
measurement update, half have weight zero and half have weight
. To resample we throw away
the particles with 0 weight and duplicate each of the survivors.
We’re left with a total weight of 1 and our surviving particles
are all in the “region of interest”. I won’t go into more detail
about resampling, there is no shortage of explainers on the
internet which focus on it.
A common technique which accompanies resampling is to add
“perturbations” to the resampled particles. That is, add a bit
of Gaussian noise to each perturbed particle’s state. This is
because we only have finite particles, so we would like to
“smear out” the survivors to more evenly cover the space.
Aside: it’s at this point that things start becoming more
of an art than a science. As you progress developing a particle
filter, more and more decisions will start to fall in the former
category
Here are the results of adding resampling and perturbing to
our particle filter:
Fair warning: particle filters fall apart in high dimensions.
There just aren’t enough particles to cover the space (curse of
dimensionality). Things fare better if things are roughly
Gaussian.
Plenty was written on the Pentagon's falling out with Anthropic this
week. This was one of the more clear-headed articles.
But the deeper problem isn't who's right in this negotiation; it's
that the negotiation is happening at all. The terms governing how
the military uses the most transformative technology of the
century are being set through bilateral haggling between a defense
secretary and a startup CEO, with no democratic input and no
durable constraints. Congress should be setting these rules. And
it should do so in a hurry.
A two-part series considering the policy implications of recursively
improving AI systems.
There is one assumption I’ll ask you to make with me, which is
that substantial automation of AI research is a near-term
possibility. This requires believing a few things. First, that AI
research and engineering is substantively composed of work like:
finding optimizations in various complex software systems;
designing and testing experiments for AI model training and
posttraining; and creating software interfaces to expose AI model
capabilities to users. Second, that a great deal of this work is
essentially reducible to the engineering of software. Third, that
AI models, while not yet geniuses, are reaching quite high levels
of human competence. Fourth, that frontier lab leadership and
staff are serious when they describe AI research automation as a
near-term goal, and that frontier lab research staff are telling
the truth when they say that AI is already writing a large
fraction of their code.
I agree with Dean that policymakers should seriously discuss recursive
self-improvement. However, his last two premises are weak.
"Competence" is too vague to be useful. Models have exceeded human
"competence" on narrowly defined math and coding tasks for 12 months.
It shouldn't be a surprise they write most code at these companies.
However, without metacognitive monitoring and self-directed planning,
these look more like another step in the evolution of compilers, IDEs,
and build tools than a drop-in labor replacement. I'm not saying that
won't happen, just that he's missing a premise.
Scott Alexander's rebuttal to the "stochastic parrot" argument
Scott argues that the "LLMs are just next token predictors" argument
is confused. It can't say anything about a model's intelligence or
world model. After all, humans are "just next sensory input
predictors".
Recently, they [Anthropic] explored how Claude predicts where a
line break will be in a page of text. Since line break is a token,
this is literally a next-token prediction task. The answer was:
the AI represents various features of the line breaking process as
one-dimensional helical manifolds in a six-dimensional space, then
rotates the manifolds in some way that corresponds to multiplying
or comparing the numbers that they’re representing ... Next-token
prediction created this system, but the system itself can involve
arbitrary choices about how to represent and manipulate data.
At Indiana University, where Erpelding worked until 2024,
professors could track whether students watched films on the
campus’s internal streaming platform. Fewer than 50 percent would
even start the movies, he said, and only about 20 percent made it
to the end
A lot of discussion around this article focused on attention span. I
think it's as much a sign of decreasing effort/standards. If I had to
guess, I'd say fewer than 50 percent of students at IU read the
assigned books in English classes.
Bacteria as a treatment for cancer. An idea I hadn't heard before.
Ewingella americana exhibited remarkably potent cytotoxic activity
with selective tumor-targeting ability characteristic of
facultative anaerobic bacteria. Mechanistic investigations
revealed that E. americana functions through a dual-action
mechanism: direct tumor cell killing and robust activation of host
immunity, leading to enhanced T cell, neutrophil, and B
cell-mediated tumor attack. Treatment with E. americana
significantly outperformed standard therapies, including
anti-PD-L1 antibody and doxorubicin, in tumor regression studies.
These are mice studies, so take with a grain of salt.
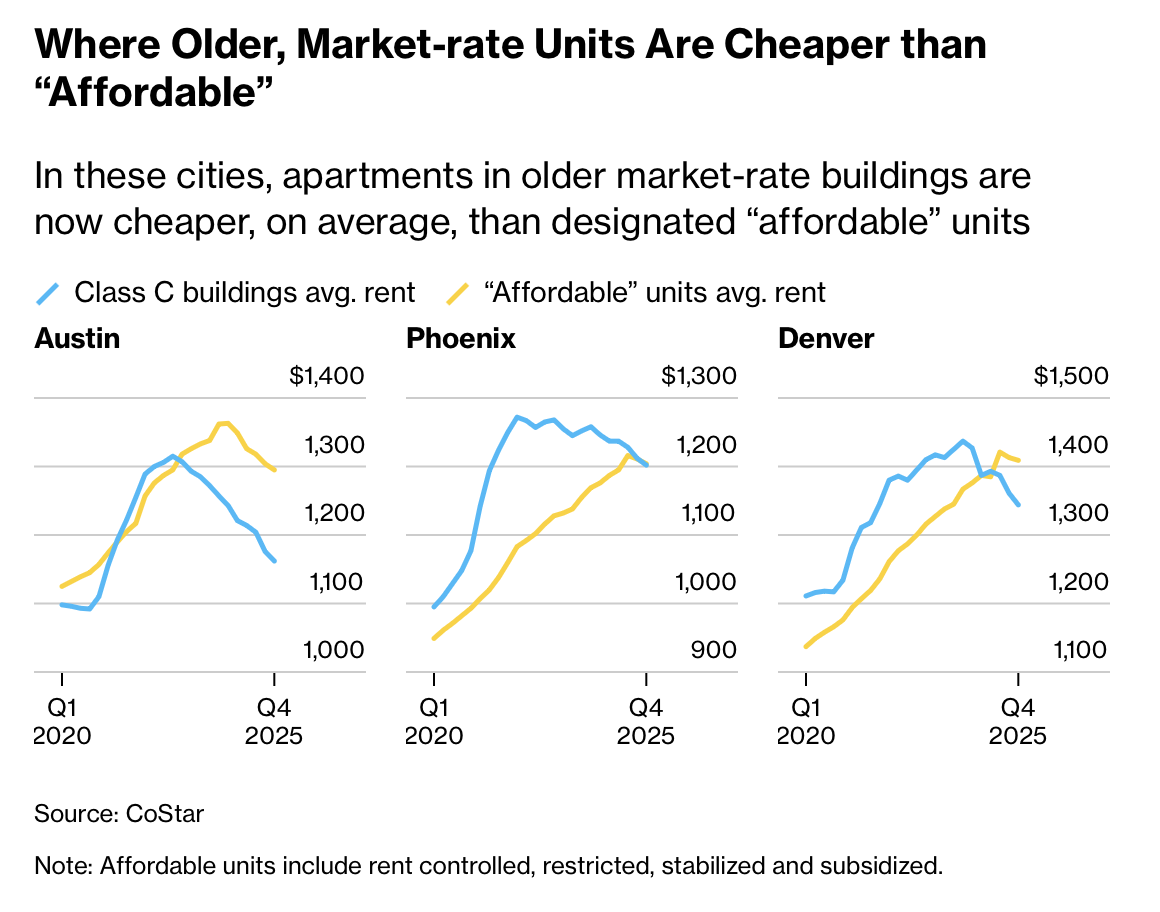
Luxury apartment construction is bringing down rent.
Building more housing brings down rent prices (not surprising). More
important, rent prices come down for Class-C housing even when most of
those additions are in luxury apartments. Austin, Phoenix, and Denver
have had an average growth in new units of 6.8%, 4.9%, and 4.3%
respectively over the past 5 years.
Every contribution to Claude Code in December by its creator was via
Claude Code.
A year ago, Claude struggled to generate bash commands without
escaping issues. It worked for seconds or minutes at a time. We
saw early signs that it may become broadly useful for coding one
day.
Fast forward to today. In the last thirty days, I landed 259 PRs
-- 497 commits, 40k lines added, 38k lines removed. Every single
line was written by Claude Code + Opus 4.5. Claude consistently
runs for minutes, hours, and days at a time (using Stop hooks)
India received $140B in personal remittances in 2024. That's more than
the profit of their largest 70 publicly traded companies combined
($120B). The U.S. accounts for roughly 30%.
The common view is that a manager proposes some technical project,
the team gets together to figure out how long it would take to
build, and then the manager makes staffing and planning decisions
with that information. In fact, it’s the reverse: a manager comes to
the team with an estimate already in hand, and then the team must
figure out what kind of technical project might be possible within
that estimate.
Central Stockholm renters face a 20-year wait due to rent control
If you’re looking for a standard rental contract in Stockholm,
you’ll have to be prepared to wait. Apartments are allocated through
a waitlist, and in 2025, new tenants in the city center had waited
an average of 21 years. Rents are regulated, and can be far below
half of market rents at the most attractive addresses.
Gemini's performance on the "Needle in a Haystack" test blows
competition out of the water.
They've got some secret sauce, maybe sub-quadratic attention, maybe RL
improvements. Unfortunately, we won't know anytime soon.
google seemingly solved efficient attention, Celeste
A 2014 interview with Walter Isaacson at Khan Academy
I'm a fan of Isaacson's books, but had never heard him speak. He's
quite charismatic. He thinks one driver of creativity which we've lost
is the connection between the arts/humanities and science/engineering
(the classic Steve Jobs mantra). Similarly, he thinks that cities
which lack creative types and a culture of humanities will fail to
produce innovation in the long run. He was more bullish on SF than
Palo Alto/Mountain View. Granted, this was 10 years ago. SF is back on
the rise, but confounded by AI. Suggest starting at 24:00
Yeah, and I'm trying to say if you look at Ben Franklin, the most
important scientist of his period. Even though you probably don't...
You know, we think of him as a doddering dude playing his kite in
the rain. Single fluid theory of electricity that comes from his
electricity experiments is up there in that century, you know, with
Newton, even. I mean, he's the best experimental scientist of his
time. Jefferson would have thought you were a Philistine if you
didn't study botany and everything else. Nowadays, people like a Ben
Franklin don't do electricity experiments.
https://www.lairdstewart.com/blog/log-dollar-utility.htmlSBF and Log Dollar Utility2025-12-30T00:00:00Z
It would have served Sam Bankman-Fried to separate utility from dollars.
I was given How Not to Be Wrong for Christmas and am enjoying it so far.
I've watched plenty of Numberphile and Veritasium and have read Stephen Pinker's
similar book, Rationality, yet it introduces many topics I haven't come
across before. One of which is
St. Petersburg paradox:
I put $2 in a pot then flip a coin
If tails, the game ends and you win the money. If heads, I double the money
I flip the coin again. Repeat step 2
Clearly you should want to play this game, as you win no matter what. The
question is, how much should you be willing to stake for the opportunity to
play? $10? $20? If you do the math you'll find that the expected value (EV) of
this game is infinite — the series diverges. Therefore in theory you should be
willing to stake any finite amount to play the game. This feels wrong. I
wouldn't stake my entire net worth, let alone one paycheck to play. The
mathematics is sound, so the paradox is of human behavior. Perhaps humans
underestimate small probabilities (I've never seen a coin land 10 heads in a
row) or perhaps the question is nonsense (no house could ever fund the other
side of the bet).
The traditional solution is to say the premise of the EV
calculation is wrong: the player should calculate the EV of their utility not of
the raw dollar amount. Further, their utility should be the logarithm of the
dollar amount. I had never heard of doing such a thing: every example in school,
every analysis of a casino/board game, every quant interview question
calculates EV directly with dollars. However, on consideration, it doesn't seem
outlandish. To rappers, money is logarithmic; lines are as often about figures
as they are absolute dollars. Further, for most millionaires it would hurt more
to go broke than it would feel good making another million. With this conception
of utility, the expected value is no longer infinite.
How does this relate to SBF? In Sam's appearance on Conversations with
Tyler, he was posed a similar question: if you could push a button with a
51% chance of doubling the number of sentient beings in the universe (e.g.,
double the number of earths) and a 49% chance of killing all living beings,
would you press it? He answered that he would press it repeatedly. Most
commentators flawed Sam for lacking empathy or being hyper-rational in his
answer. From what I know from Going Infinite the former is fair. But I
don't think the latter is. If Sam calculated his EV using the logarithm of the
number of living beings (which I'm starting to think is correct), he wouldn't
have arrived at the same conclusion and his answer would have been more
wonky/"hyper-rational".
Taking this a step further, could solve some of the problems/paradoxes that
arise with longtermist utilitarian ideas. If you're not familiar, some people
argue that we should not (or should only barely) discount the utility of future
sentient being's lives with time. Therefore since there could be many more
living people in the future we should prioritize protecting the future above all
else. Therefore, even if you choose not to discount with time, you could still
avoid some of the problems with expected values and infinity if you consider
utility to be the logarithm of the number of beings. Surprisingly, in all I've
read about utilitarian philosophy I've never heard this idea, though I'm sure
I'm not the first.
For another time, but you could obviously extend this to SBF's Alameda Research.
I'm curious to what extent, if at all, hedge funds separate EV/utility from
dollars.
School cellphone bans likely have a small, positive impact on test performance
A recent difference in difference study finds Florida's 2023 secondary school
cell phone ban increased test scores by 0.6 percentiles; a smaller effect than I
expected.
In his conversation with Kenneth Rogoff, Tyler Cowen suggests an alternative to
Fischer Random Chess: select starting positions from a database of equal
positions 2 or 4 moves in. In Fischer Random, the back rank is randomized
emphasizing over-the-board play over preparation. Cowen's alternative achieves
the same goal, but results in more standard positions which observers can
empathize with. An interesting idea I hadn't heard before.
I was given How Not to Be Wrong for Christmas and am enjoying it so far.
I've watched plenty of Numberphile and Veritasium and have read Stephen Pinker's
similar book, Rationality, yet it introduces many topics I haven't come
across before. One of which is
St. Petersburg paradox:
I put $2 in a pot then flip a coin
If tails, the game ends and you win the money. If heads, I double the
money
I flip the coin again. Repeat step 2
Clearly you should want to play this game, as you win no matter what. The
question is, how much should you be willing to stake for the opportunity to
play? Blog post with the answer and related thoughts
here.
I like how Casey Handmer and Terraform think about resumes
I could look at two identical candidates with similar career paths, and have no
way of knowing that one of them built a jet engine in their living room. Their
resumes are very similar and have no ability to choose between them. But a
single photo of them in front of their own jet engine would tell me 95% of what
I need to know to make a job offer. It would pretty much instantly put them on
the top of the screening pile too
For Terraform, send us your one pagers. Ideally they will contain photos of
awesome hardware you personally created, together with a brief and informative
summary of how the project relates to your desired role with us
Gregory Clark's The Son Also Rises gets repetitive but is worth the read.
Clark's central insight is that if you track the prevalence of a surname in an
elite institution, it remains over- or under-represented much longer than
traditional social mobility rates would suggest. The majority of the book is
spent showing this holds regardless of time-period or location.
To explain this, Clark models status as latent variable. This variable is
"indistinguishable" from genetics, depending only on that of the parents and
randomness. The variable determines, again with random noise, observable
outcomes like income or educational attainment. Traditional methods measure
observable variables regressing to the mean, and therefore overestimate the pace
of social mobility.
Clark concludes that status is mostly inherited, government efforts to increase
social mobility have largely failed and as long as marriage is assortative
(high-status people marry other high-status people) social mobility will remain
slow.
Bryan Caplan's The Case Against Education argues higher-ed is mostly
signaling.
When we look at countries around the world, a year of education appears to raise
an individual’s income by 8 to 11 percent. By contrast, increasing education
across a country’s population by an average of one year per person raises the
national income by only 1 to 3 percent. In other words, education enriches
individuals much more than it enriches nations.
Correcting for underlying cognitive ability, Caplan estimates 60% or more of the
education-wage premium is
the sheepskin effect. In particular, he argues education signals
intelligence, conscientiousness, and conformity. Firms pay this premium, so an
open question on my mind is why probationary periods aren't more common.
An interesting multi-part retrospective on 2010s culture from a little-subscribed Substack
Before dropping out to found Theranos, Elizabeth Holmes had only two semesters’ worth of chemical engineering, but that was irrelevant, as the stamp of Stanford became the only relevant factor in her ridiculous narrative of entrepreneurship ... Unlike Holmes, Javice collected her degree, but classmates told Fortune she more or less spent her time collecting stamps, as she finagled her way into a prestigious incubator for entrepreneurship that the university hosted
There was a fairly recent tweet expressing outrage that Columbia University was revoking degrees to sanction student activists, and it said something like, “How can they revoke degrees? Degrees are earned.” While the work of attending classes and completing assignments and passing exams does seem to show the inherent value of a degree, the autodidact gets no respect for a reason. The conferral of a diploma, the recognition by a university and preferably a university with a good name, is what makes that work “real”
Trader Joe's played a major role in popularizing wine (particularly Californian wine) in America. In 1970, Trader Joe's was the largest wine retailer in California.
Prediction Error Minimization Theory suggests the brain works by refining a world model to minimize the difference between its prediction and what happens next. I had never heard of this; it's supervised learning for cognitive science, which seems too simplistic.
Last month, I shared an Atlantic article about the De Beers diamond cartel. They just ran a paid post in the NYT. Like their previous campaigns, it doesn't advertise any product; this time they mythologize the story of a single diamond discovery.
The first AI image that made my jaw drop. Courtesy of Nano Banana Pro. Past models made photorealistic people look airbrushed and glossy; we've crossed the uncanny valley completely.
Taiwan's central bank plays a heavy-handed role in devaluing its currency to subsidise exports. Good news for Joey!
Critics say the central bank prioritises export growth with single-minded fervour, an approach which harms the country in several ways. First, keeping the currency weak subsidies exporters at the expense of importers. In Taiwan, where the vast majority of both food and fuel (for vehicles and power plants) is imported, this acts as a transfer from poor households to the owners and employees of exporting firms. Taiwanese workers have good reason to feel aggrieved. Labour productivity has doubled since 1998, yet unlike in most rich countries or even in wage-suppressed China, pay has not risen in tandem. Taiwanese unit labor costs, a measure of what workers earn per unit of output, have fallen by 25% over the same period.
A Taiwanese Big Mac, it turns out, costs 56% less than an American one. America is a fraction wealthier than Taiwan, but that affects things only on the margins. Adjusting for this, we calculate that the Taiwan dollar is 55% undervalued, the most of all 53 currencies we track.
I just started reading Gregory Clark's The Son Also Rises. He tracks social mobility using the relative prevalence of surnames in elite institutions. The rates he calculates are lower than most other estimates.
Thus the representation of surnames among both attorneys and physicians in Sweden suggests a similar pattern: social mobility in Sweden is much slower than conventional estimates suggest, even for very recent generations. A second surprising finding from the surname distribution of Swedish physicians is that not only are true social mobility rates slower than conventionally estimated, but they are no faster now than they were in the early twentieth century. The enlargement of the political franchise and the institutions of the extensive welfare state of modern Sweden, including free university education and maintenance subsidies to students, have done nothing to increase rates of social mobility.
https://www.lairdstewart.com/blog/online-masters.htmlOnline Master’s Programs are Worthless2025-10-11T00:00:00Z
When I say “Online Master’s” I mean fully remote programs for
professionals from accredited institutions. For example, JHU Engineering for Professionals,
where I’ve taken courses. These programs provide value via
Instruction (materials and guidance provided by the
professor)
Signaling (proxy for intelligence/conscientiousness – for
career advancement)
The introduction of reasoning models represents a drastic
decrease in the value of both factors. First, equivalent
instruction is possible via the combination of publicly
available syllabi and recorded lectures in concert with LLM
tutors.
Online MS
Internet
Reasoning Model
Syllabus/Homework
X
X
Lectures
X
X
Tutoring/Feedback
X
X
Second, the elephant in the room, reasoning models can get As
in most classes. I’ve tested these models on physics, math, and
CS problems and suspect this is the case for all STEM subjects.
If a student wishes to do so, they can get an A with almost no
effort and without learning anything. If they haven’t already,
employers and PhD admissions committees will soon realize that
online Master’s degrees are only worth the student’s word.
I predict online Master’s programs will lose 90% of their
value in the next year as LLM tutors improve and employers wake
up. Assuming these programs won’t suddenly fall 90% in price, I
expect enrollment to fall.
What next?
I won’t be taking any more classes at JHU. I’m toying with
the idea of finding a group of coworkers or friends who want to
find a textbook or recorded online course to study together. If
I were in charge of my company’s HR department, I would stop
compensating employees for online coursework. I would also stop
counting online Master’s programs awarded after 2025 as “years
of experience” when calculating salary scales. Finally, if I
were a director making hiring decisions, I would weigh online
Master’s coursework equally to a prospective hire claiming to
have self-taught a course via a recorded lecture series and LLM
tutor.
Given the following observations:
What previously costed $2,500 (assuming instruction is 1/2
the value of these courses) can now be offered for the price of
an LLM subscription.
Demand for post-graduate education will increase as students
drop out of (or never begin) these programs
There’s an opportunity here for a startup (or open source
project). I’m imagining a service that organizes publicly
released lectures and syllabi and matches students with others
in their city to form study groups. What remains is recovering
the lost signaling value. Perhaps peer reviews or in-person
final exams at testing centers.
The De Beers diamond cartel ran an advertising campaign to dissuade people from selling their diamonds
"It is conservatively estimated that the public holds more than 500 million carats of gem diamonds, which is more than fifty times the number of gem diamonds produced by the diamond cartel in any given year. Since the quantity of diamonds needed for engagement rings and other jewelry each year is satisfied by the production from the world's mines, this half-billion-carat supply of diamonds must be prevented from ever being put on the market. The moment a significant portion of the public begins selling diamonds from this inventory, the price of diamonds cannot be sustained. For the diamond invention to survive, the public must be inhibited from ever parting with its diamonds."
The fastest buildout of nuclear reactors took place in France in the 70s and 80s
“During the 1980s, France increased the number of reactors in commercial operation from 15 to 55. Even China, with the world’s most streamlined regulatory process and developed industrial base, has failed to match this record”
“In the 1970s, France was building nuclear reactors at one-third to a half of the pre-interest costs that new reactors in the US had risen to amid toughening environmental and safety regulations.”
Paul Erdos' mathematical output heavily relied on stimulants
“Erdos first did mathematics at the age of three, but for the last twenty-five years of his life, since the death of his mother, he put in nineteen-hour days, keeping himself fortified with 10 to 20 milligrams of Benzedrine or Ritalin, strong espresso, and caffeine tablets. 'A mathematician,' Erdös was fond of saying, 'is a machine for turning coffee into theorems.'"
In relative terms, data center freshwater consumption is unconcerning
0.19% of America's freshwater consumption in 2023 went towards powering and cooling data centers. For reference, that is 10% of the freshwater lost due to indoor household leaks. If forecasts are correct and data center electricity usage triples by 2030, their additional water consumption will be equivalent to the US producing 5% more steel. At the personal level, each day the average American consumes (indirectly) the equivalent of 800,000 chatbot prompts in water. When putting together this roundup, I realized that I've actually met Andy before. He's the director of EA DC.
Takeaways from Andrej Karpathy on Dwarkesh Podcast
Andrej believes that LLM's encyclopedic knowledge is holding them back. He believes removing much of this encyclopedic knowledge, leaving behind a "cognitive core" will improve performance. Tool use (e.g., connecting to Google) would make up for lost factual knowledge.
Andrej discounts the possibility of a discrete intelligence explosion. He views the impacts of AI as an extension of ongoing computer automation.
He's starting an AI education company. Incidentally, I wrote a blog post making the case for something exactly like this.
Multi-scale emergence can be quantified using the entropy of a system's transition probability matrices
A very interesting non-expert summary of a paper published this month (I haven't had the chance to read the technical paper). At a high level, you can describe any system as a Markov Chain and represent its different scales as groupings of its events. Then, take the transition probability matrix of each grouping and score them using an entropy-based measure to quantify their "irreducible causal contribution".
The US and Canada accidentally kick-started India's nuclear weapons program
The US and Canada provided India with a heavy-water research reactor through the Atoms for Peace program. India then built a reprocessing facility and repurposed the reactor to extract Plutonium-239 for its first nuclear test. India argued that its test was a "Peaceful Nuclear Explosion" and did not violate the stipulation of the deal that the reactor should only be used for peaceful purposes.
Pew Research survey finds increasing distaste for sports betting across America
10% more Americans see sports betting as bad for society than in 2022. This trend is growing across every demographic. 43% say legal sports betting is bad for society, while only 7% say it is good. An equal percentage of college and non-college graduates bet on sports (22%). Sports betting is more common among young people and those with higher incomes.
Gemini has met Larry Page’s 2000 definition of artificial
intelligence
“Artificial intelligence would be the ultimate version of
Google. If we had the ultimate search engine it would understand
everything on the web it would understand exactly what you
wanted and it would give you the right thing. That’s obviously
artificial intelligence; be able to answer any question
basically because almost everything is on the web right and so
we’re nowhere near doing that now. However we can get
incrementally closer to that and that’s basically what we work
on and that’s tremendously interesting from an intellectual
standpoint … so I expect to be doing that for a while.”
At the time of Gmail’s launch in 2004, Bill Gates couldn’t
imagine needing more than 1G of email storage
“How could you need more than a gig? What’ve you got in
there? Movies? Power-Point presentations?”
Gemini 2.5 Pro can one-shot linear programming word
problems
Given a linear programming problem with four constraints, Gemini correctly
translates the constraints to a Python program using scipy’s
linprog library. Two years ago, hand-massaging LLMs to do named
entity recognition and formulation of constraints was an active
area of research. NL4OPT
was a competition to do just this. I came across this while
looking into creating my own NL4OPT tool. I posed the problem to
Gemini expecting it to fail. Needless to say, I was surprised.
Tool use is the past, present, and future. Its interface is
Python.
Above-market government salaries can compromise economic
productivity
“In many countries, public employees enjoy considerable job
security and generous compensation schemes; as a result, many
talented workers choose to work for the public sector, which
deprives the private sector of productive potential employees.
This, in turn, reduces firms’ incentives to create jobs,
increases unemployment, and lowers GDP…. [Calibrating the model
to Greece] we find that a 10% drop in public sector wages
results in a 3.8% increase in private sector’s productivity, a
7.3% drop in unemployment, and a 1.3% increase in GDP.”
A larger fraction of Europeans die from preventable heat
death than the fraction of Americans who die from firearms
“Most of this death is preventable. The technology that
prevents it is air conditioning. Barreca et al. (2016) find that
heat deaths in America declined by about 75% after 1960, and
that ‘the diffusion of residential air conditioning explains
essentially the entire decline in hot day–related
fatalities’”
Lex is out of his element in economics/politics. Dwarkesh is
energetic, but asks too many niche, drawn-out questions
(cynically, to show off). Tyler asks sharp, one sentence
questions, guiding the conversation while letting the guest
talk. In his episode
with John Arnold, Tyler brought up one interesting question
about solar: How do we prepare for volcanic events occurring
every ~150 years? This is too long a horizon for the market to
solve. How can the government ensure some base load of natural
gas or nuclear is always available over 100s of years? Tyler
also sees NIMBYism as nuclear’s greatest obstacle.
Aircraft carriers may already be a relic
“Similarly, anybody who’s read even news articles about
hypersonic weapons should decide that buying more aircraft
carriers is not a good thing. But we do need some of those
resources shifted to this new defense ecosystem that’s very
experimental, that’s building swarming weapons.” — Christopher
Kirchhoff
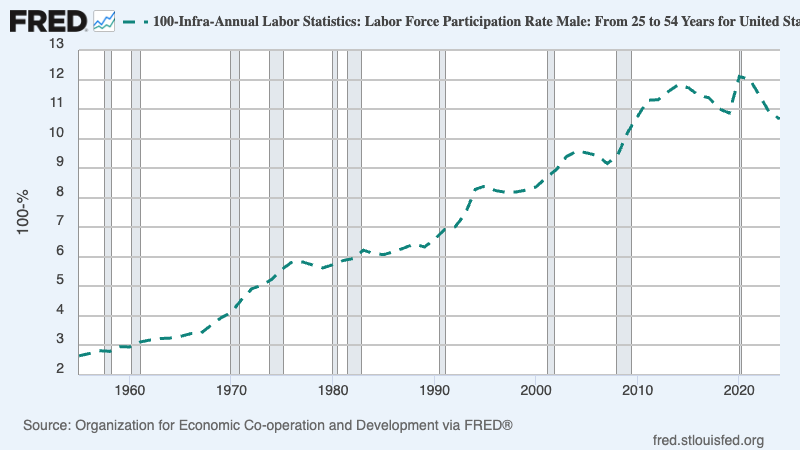
️️10% of 25 to 54-year-old men are not seeking employment
Age-graded classrooms are the worst form of schooling …
except for all the others
Age-graded classrooms work because they optimize student
motivation. Peer pressure is a great motivator; so while often
inefficient, there is a reason lock-stepping students onto the
same track as others has become the standard. The author
estimates that around 5% of students are intrinsically motivated
enough to teach themselves (he calls them no-structure
learners). This is why considering selection bias is so
important. I was recently excited to learn about Math Academy. I fear now
their results may boil down to selection bias.
“Here’s something you have to remember. It’s easy to
cherry-pick in education. If you want to start a school to prove
that penguin-based learning is the future, that penguin
meditation and penguin-themed classrooms are superior to the
stuffy, traditional, obsolete schools we have now, you can. It’s
simple. Find a way to only accept no-structure and very
low-structure learners. Then start your school. Do your penguin
meditation, make sure there’s a basic structure for learning
core academic skills, and you’re set. The results will be great,
you can publish articles about the success of your method, if
you’re lucky you’ll get some of that sweet sweet philanthropy
money”
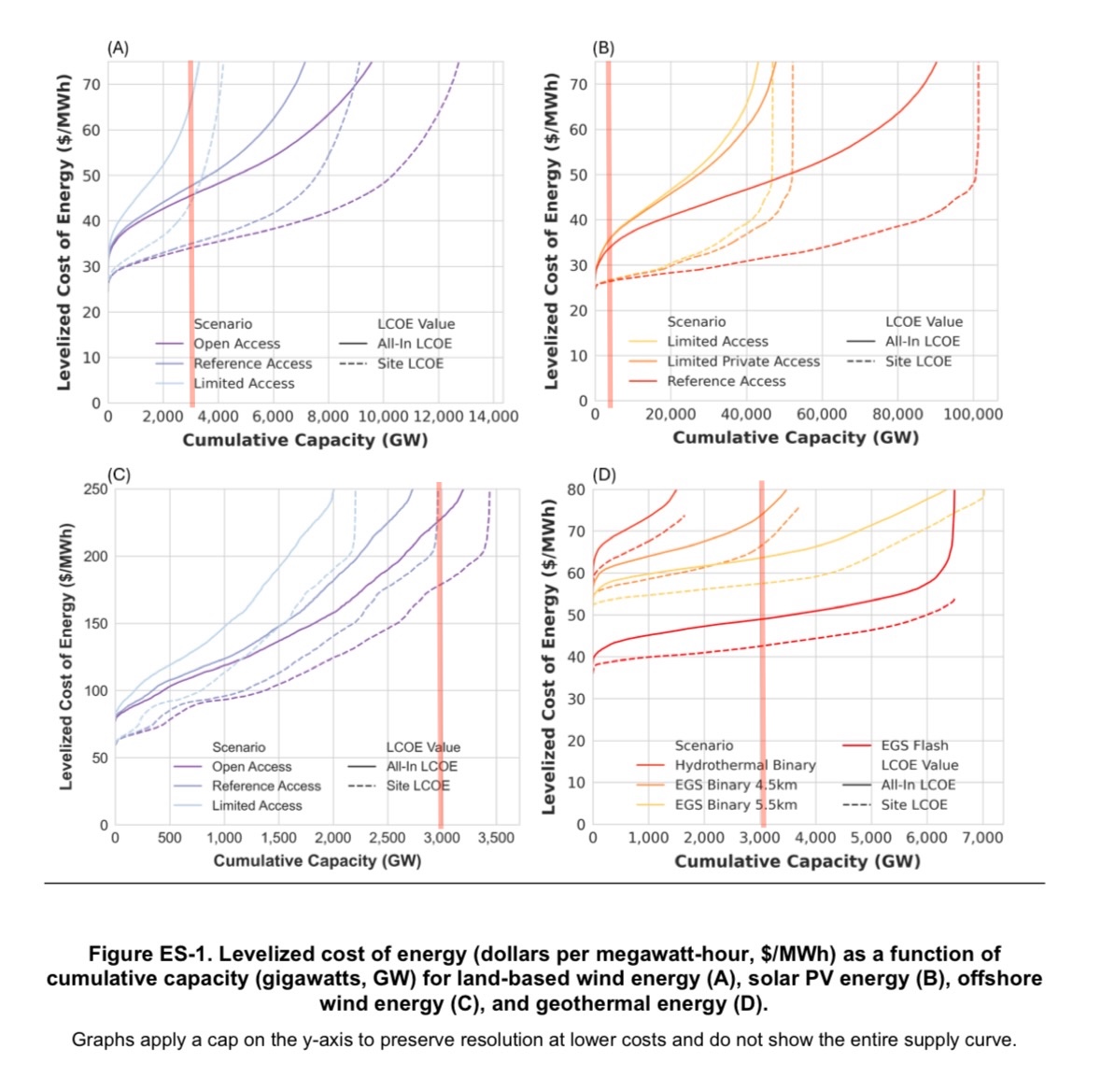
Renewable
Energy Technical Potential and Supply Curves for the Contiguous
United States: 2024 Edition
Note the y-axes are not the same. For solar (B) this is the
nameplate capacity. It is common to assume a capacity factor (%
of time the sun is shining) of 20% and therefore 5x the required
wattage is required to be built in nameplate capacity (along
with batteries, transmission, etc.). For reference, the US total
primary energy consumption is 94
quadrillion Btu, equal to 3,100 GW on average. I’ve placed
vertical lines at this point. Eyeballing this, solar and
land-based wind look good while offshore wind is a no-go. I
don’t know enough about the types of geothermal to comment
there.
https://www.lairdstewart.com/blog/2-years.htmlReflections on Two Years Of Software Engineering2025-08-27T00:00:00Z
This advice is general, but probably biased by my background
with legacy Java applications.
Chesterton’s Fence: A hiker comes across a small wooden
fence on a beautiful hillside which anyone could step over. He
removes it to restore the place’s beauty; it wouldn’t stop
trespassers anyway. Once he has left, over the next months the
cows from the neighboring farm eat all its grass and trample it
into a muddy slope. When building software, if you encounter
something that seems poorly designed, figure out why it was
designed that way before refactoring or removing it.
Pareto Principle (power law): Most real-world relationships
are non-linear. E.g., 80% of revenue comes from 20% of
customers.
One example of the Pareto Principle is methods which speed up
typing:
Touch typing
Vim key bindings
Dvoark layout
Ergonomic keyboard
Touch typing will get you 80% of the way to a “pro” typist
while Vim keybindings will get you another 15%. Changing
keyboard layouts could help a little beyond that. Although touch
typing provides 5x more value than Vim keybindings, it’s about
the same difficulty to learn. My suggestion: if you can’t
already touch type, learn now. If you can, learn vim
keybindings. Don’t worry about keyboard layouts, taking “The
Missing Semester”, reading books about software development, and
networking are all better uses of your time.
Minimize configuration. “Every line of configuration is a
liability” - ThePrimagen. It’s tempting to spend a lot of time
configuring your IDE, terminal emulator, and shell. First,
remember Chesterton’s Fence – the creators of dev tools designed
their tool’s features and configuration intentionally (often for
their own use!). Another drawback is that you will inevitably
need to switch computers, help colleagues, or ssh into a server.
These are all more difficult if you can’t use default
configurations. My suggestion: when starting with a new tool,
use its vanilla configuration for the first month (or more).
Learn its core features before configuring settings or
installing plugins.
Learn the command line versions of tools
They are more feature-rich
They can be scripted
Amortize costs of learning the CLI (terminal emulator,
shell) and supporting tools (e.g., tmux, man) across multiple
applications.
Try the simple/open source tool first. More often than not it
has all the functionality you’ll need and is easier to learn. If
you discover a functionality it doesn’t have, you’ll be more
prepared to choose a paid offering. For example, VisualVM has
suited all my Java profiling needs so far.
I read a few books on software engineering. It was a good use
of my time. Ranked (power law applies here):
A Philosophy of Software Design – John Ousterhout
Code that Fits in Your Head – Mark Seemann
Working Effectively with Legacy Code – Michael Feathers
Design Patterns – Gamma, Helm, Johnson, Vlissides
Refactoring for Software Design Smells – Suryanarayana,
Samarthyam, Sharma
Clean Code – Robert Martin
And finally, a few tips I try to follow (but beware pithy rules
like these)
Make simplicity the number one priority
Use pure methods and immutable data whenever possible
Favor composition over inheritance
Favor strong typing
https://www.lairdstewart.com/blog/tokamak-drift.htmlNotes on Grad-B and Curvature Drifts in Tokamaks2025-07-13T00:00:00Z
Motivation
If held in a plasma of high enough temperature and density,
light ions will eventually fuse. Magnetic confinement is an
approach to controlled fusion which achieves these conditions
using the magnetic force. This force acts perpendicular to ions’
velocity and the magnetic field, causing them to travel in
helices around field lines. Tokamaks bend these field lines into
a torus, trapping ions like beads on a bracelet. Once this trap
is set, ions are injected and heated with electromagnetic
radiation to achieve fusion conditions. Unfortunately, the
centers of ion orbits drift away from their original field lines
causing them to escape confinement. The addition of a poloidal
(short way around the torus) component to the magnetic field
negates the effect of this drift. This post derives a
representative magnetic field using a toroidal/poloidal
coordinate system and motivates the additional poloidal
component by simulating the trajectory of a single particle.
Toroidal Coordinate
System
It’s much simpler to formulate a tokamak’s magnetic field
using a toroidal/poloidal
coordinate system because its geometry mirrors the
problem’s, encapsulating its complexity. This system describes
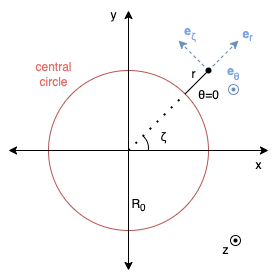
locations relative to a “central circle” of radius using three coordinates: , , and . measures the toroidal angle
(long way around), the
poloidal, and the distance
from the central circle.
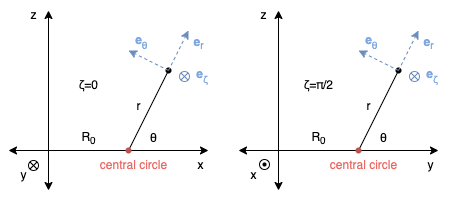
Figure 1. Toroidal Coordinate System Top View
Figure 2. Toroidal Coordinate System Side View
The translation to and from Cartesian coordinates is given by
Where is the
C/Python function which returns the angle between the positive
x-axis and the point in
the plane. Notice that is the signed
distance to the central circle in the xy-plane where a negative
value indicates the point is within the circle.
The unit vectors in this system (blue vectors in the
figures), expressed in Cartesian coordinates, are
Therefore, to translate a field vector with base (, , ) and components (, , ) to Cartesian coordinates, the base
can be found using the translation above, and the vector using
the scaled unit vectors:
Note On Handedness
If you pay close attention to the figures above, you’ll notice
that the coordinate system is left-handed. That is, you can
point your left thumb in , left index in and your middle
will naturally point in . This means that the
cross product between vectors in order (, , ) does not act like it does
between (, , ). If using equations defined for a
right-handed system, you would need to account for this with
appropriate negative signs. Alternatively, you can make this
system right-handed by measuring or in the opposite direction.
Since I only use this system to define the magnetic field and
not do any calculations, this isn’t a concern.
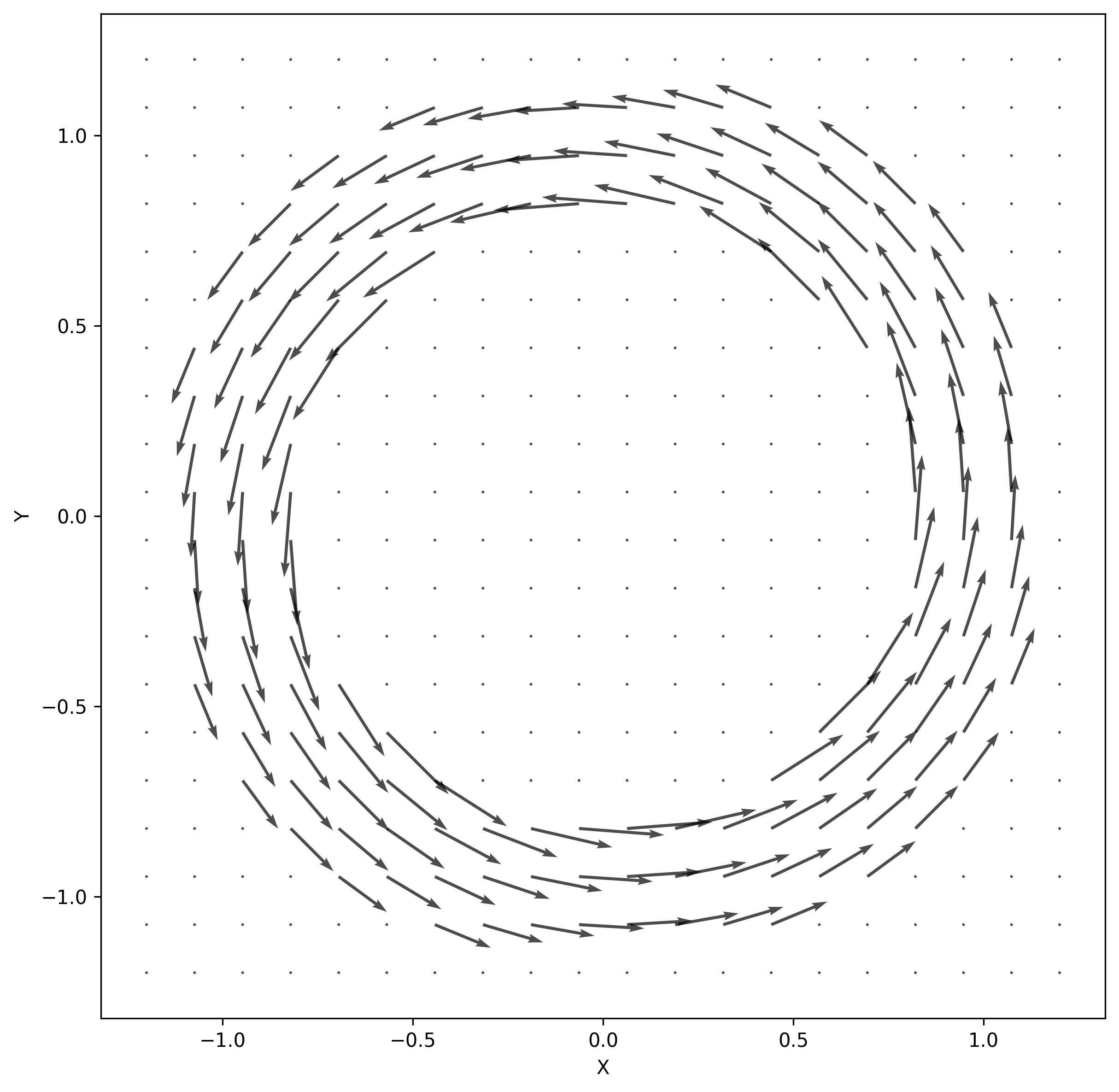
Basic Tokamak Magnetic
Fields
The simplest field to imagine is a torus with constant
magnitude in the
(toroidal) direction.
Where is the poloidal
radius. Remember that the major radius is implicit in the coordinate
system. Unfortunately, such a field is impossible to construct.
Consider the integral around the central circle. Since the field
is constant, the integral will be proportional to the loop’s
radius. The integral over a loop with a slightly larger radius
will be slightly larger. This contradicts Ampere’s law which
tells us the integrals must be equal because the same amount of
current (from the toroidal field coils) passes through each
loop. In order to obey Ampere’s law, the magnitude of the
magnetic field must vary with :
Accounting for this fact leads us to the field: Since . Choosing a
numerator of normalizes
this so that the field along the central circle .
Figure 3. Toroidal Magnetic Field, z=0
Look closely, and you’ll see that the length of the vectors
on the inner radius are longer than those on the outer
radius.
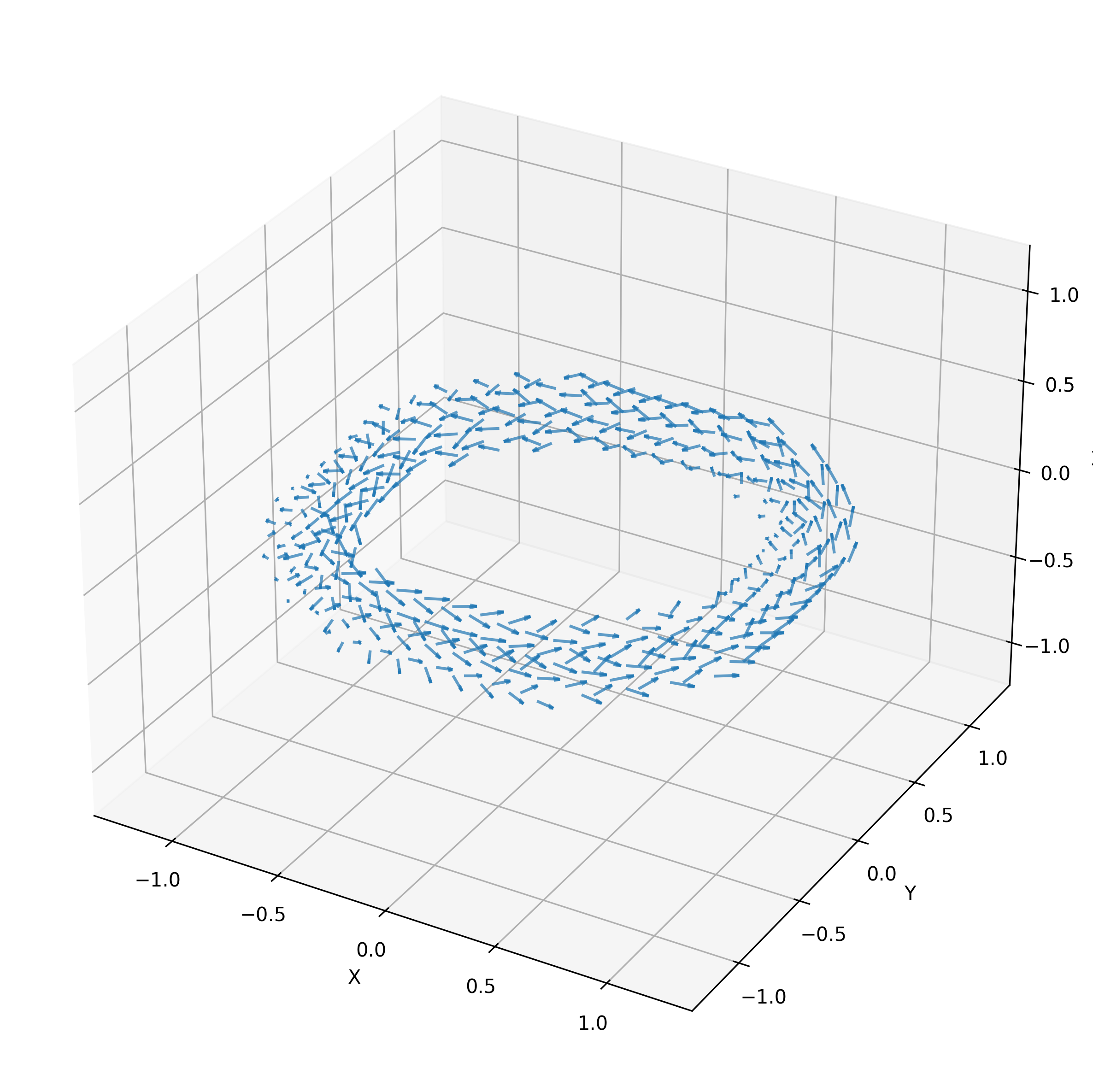
The addition of a poloidal field helps mitigate particle
drift (I’ll explain why in the next section). It’s not possible
to create such a magnetic field with external coils, so instead,
Tokamaks drive a toroidal current through the plasma itself. The
precise mechanism (induction, neutral beam injection, or
electromagnetic radiation) is not important here. Assuming this
current density is
uniform:
Ampere’s law tells us that this poloidal field is
proportional to the minor-distance from the central circle,
. Because the magnetic field
in a vacuum linear, the toroidal and poloidal fields
can be combined by
addition:
I normalize the poloidal term, so it varies from
0 at the central circle to at
the surface.
Figure 4. Toroidal and Poloidal Magnetic Field
Particle drift
There are two causes of particle drift due to complexities of
the magnetic field. The first is caused by the magnetic field
varying in magnitude. This is called grad-B drift. It causes the
orbital centers of particles to move with velocity:
Where is the
particle’s velocity perpendicular to the field line, is the Larmour radius (radius of
a single orbit around the field line), and is the magnitude of
the magnetic field. The
indicates that the drift is positive for ions and negative for
electrons. To calculate this drift for the toroidal field,
consider an ion anywhere in the poloidal cross-section at . Using the fact that when
, and that , we can write the
gradient of the field in Cartesian coordinates.
The grad-B drift for an ion with charge and mass is then
By argument of symmetry (we could have oriented the x-axis
however we like) the ion will experience this same drift
everywhere in the torus. Notice this is a constant, so this
drift is the same for any particle trajectory.
The second type of drift is due to the curvature of the field
and arises from the centrifugal force: Where is
the vector pointing from the center of the torus to the
particle, and is
its velocity along the magnetic field line. Now consider an ion
at , that is,
along the -axis so that . The curvature drift will be
If the particle has a non-zero -component, this becomes more
complex since and
is no longer
perpendicular to .
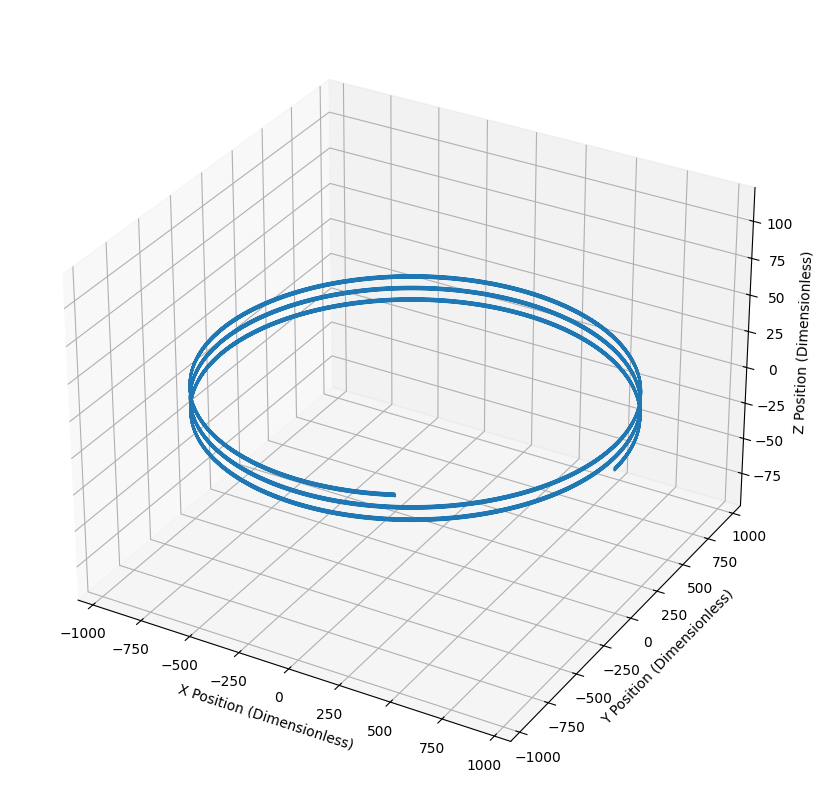
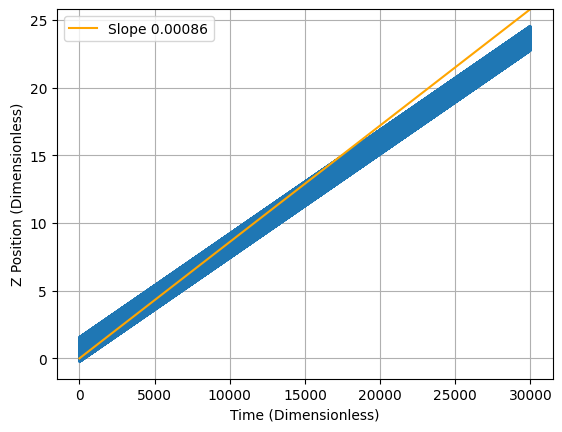
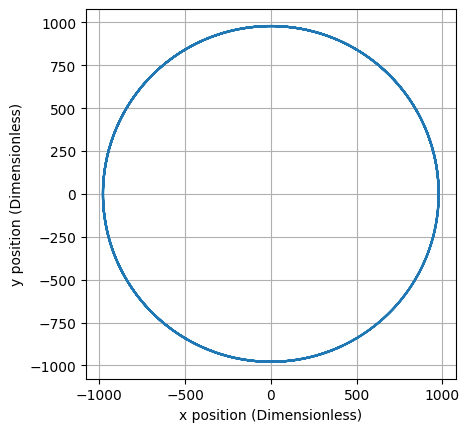
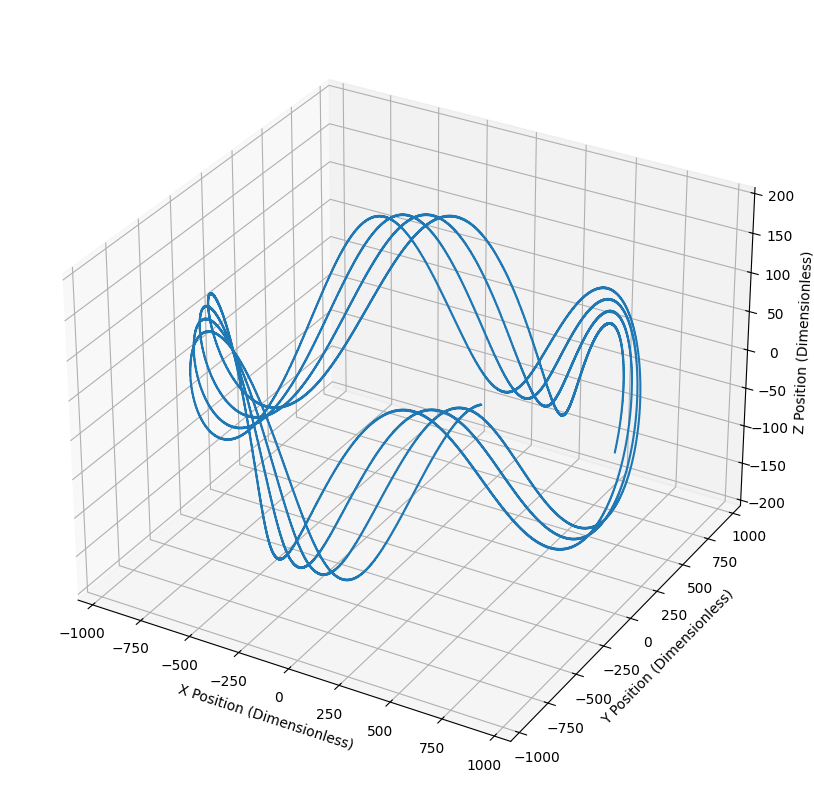
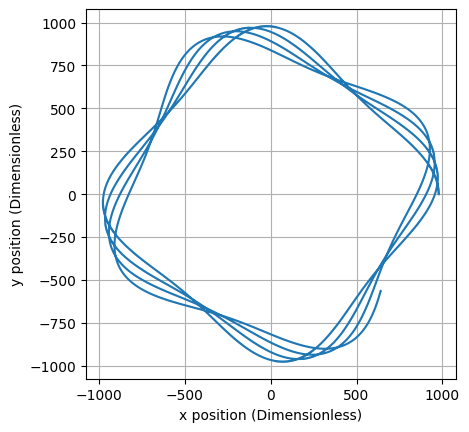
The net effect in the toroidal field is that ions traveling
in the direction of the field lines will drift in the direction until they escape
confinement. This is obviously a concern. Fortunately, the
addition of a poloidal component of the magnetic field solves
this problem. The twisting path causes ions to spend an equal
amount of time in the top () and bottom () of the torus. While the ion
is in the top, its upward drift causes it to move away from the
central circle, but while it is in the bottom, its drift bring
it back towards the central circle. Therefore, on average, there
is no overall drift!
Simulation Setup
Assume the effect of gravity is negligible and the electric
field is zero. The ion experiences only the magnetic force:
The ion’s trajectory will follow this ODE. This cannot be
solved analytically, so I use an adaptive Runge-Kutta method to
solve it numerically. We can simplify the code by
non-dimensionalizing this equation. That is, replace each
component of the equation with a characteristic unit (denoted by
a subscript ) multiplied by a
non-dimensional term (denoted by ~). For example,
Fix , , and to scales relevant to the
problem, and then choose so
that this pre-factor becomes 1. Characteristic length is then
derived from the other units.
Magnetic field: T
(Typical Tokamak field)
Electric charge: C (proton
charge)
Mass: kg (proton
mass)
Velocity:
m/s (typical thermal velocity in a fusion reactor)
Time:
s
Length:
m
The simulation will use this simplified, non-dimensional
equation. To recover a dimensional-quantity, simply multiply the
non-dimensional value by the characteristic unit.
I use the following parameters and initial conditions:
Major radius:
Minor radius:
Initial position:
Initial velocity:
Particle Trajectories
At the stating time, . Since
, we
have that , so the
drift velocity should be roughly
In the toroidal field, the particle follows a circular path
while drifting upward as expected. The rate of this drift is
slightly smaller than .
I don’t know why. Remember that while the particle loops the
torus, it travels in a helical path around the field line, this
is why the line in Figure 6 is thick.
The addition of a poloidal field adds a periodic poloidal
motion to the trajectory. The amplitude of the particle’s
oscillation in the -direction
does not grow with time, so the drift has been mitigated.
Figure 8. Toroidal and Poloidal Field: Particle Trajectory XYZ
Figure 9. Toroidal and Poloidal Field: Particle Trajectory Z
Figure 10. Toroidal and Poloidal Field: Particle Trajectory XY
Resources
I’ve only provided the analytic form of these drifts to keep
this short. If you’re looking for a conceptual understanding, I
suggest chapter 4 of “The
Future of Fusion Energy” by Parisi and Ball. For an
introduction to the Runge-Kutta method, see Chapter 6 of Toby
Driscoll’s “Fundamentals
of Numerical Computation”.
https://www.lairdstewart.com/blog/bayes-rule.htmlNotes on Bayes’ rule2025-05-14T00:00:00Z
Consider a rectangular dartboard with two circles and drawn on it. A monkey is throwing
darts at the board, and they fall randomly within it. The
probability that the dart falls within the circle labeled is its area divided by the area of
the rectangle, . Now
imagine you’re facing the other way and the money throws the
dart. The bartender tells you it landed in . What is the probability it also
landed in (i.e., in the
purple intersection)? It’s hopefully intuitive this is the area
of the purple section divided by the red section, .
Bayes’ rule formalizes this:
Where is the
probability of event
occurring and is the
probability of occurring
given that occurred. Plugging
in the probabilities from the dartboard example, we get the
result we expect:
One way to derive Bayes rule is by starting with the
definition of joint probability:
If you aren’t convinced of this fact, consider the dartboard
again. You can think of
as what % of the red circle is covered by the purple section.
Or, in other words, the ratio of the area of the purple section
to that of the red section. If we then multiply that by the area
of the red section, we’re left with the area of the purple
section. You can use the same logic to convince yourself of the
third term in (3). Finding Bayes’ rule is as simple as dividing
(3) by .
Let’s take a step back, and think more about (1). is a probability and therefore
bounded between 0 and 1. How does this fraction ensure this is
the case? It’s clear that it won’t be negative as the three
components are all positive. But if , why wouldn’t this fraction
grow to infinity? The reason is that which is
strictly less than or equal to .
In (1), is called the
prior and the posterior
since was our belief about
the probability of event
occurring before observing the event , and is our belief about its
probability after (prior to) observing .
https://www.lairdstewart.com/blog/likelihood.htmlNotes on Likelihood2025-04-16T00:00:00Z
Take a Gaussian probability distribution
This is a function of and is
parameterized by and . If we instead consider the
expression on the right as a function of and , parameterized by , we have the likelihood function
This is the definition of the likelihood function.
I’ll emphasize that the expression on the right hasn’t
changed. A few things fall out of this 1) Previously the
integral of (holding , constant) over was 1. Now if we integrate over and (holding x constant) there is
no reason to expect the integral is still 1. 2) evaluated at is a likelihood.
If happened to be
parameterized by
and evaluated at the result
would be the same (since the expression is the same). Therefore,
the value of evaluated at
is the likelihood of its
parameters parameterized by . That’s a long-winded way to say
is a likelihood. (Remember
it is the integral of which
is a probability: ).
So what does it mean? Look at the line on this surface for
. Notice that near it has a low likelihood. As
increases, its
likelihood increases for a bit and then declines again. Consider
three points along that line (, ) = (5.5, 0.2), (5.5, 1), (5.5,
2). How did we calculate the value of at each of these points? We just
plugged in these
pairs along with into the
expression above. Let’s visualize our doing that, but letting x
vary again (notice these curves are PDFs now).
The value of our likelihood surface for each combination
is the
intersection of the red line with each of these PDFs. Orange
performs the best. Even if we centered the green PDF on it would still not have as high a
value as the orange curve. So we can think about the values of
the likelihood function like this: “how well does this pair of
parameters fit the
data point ?”
That brings us to Wikipedia’s definition: “A likelihood
function (often simply called the likelihood) measures how well
a statistical model explains observed data by calculating the
probability of seeing that data under different parameter values
of the model.” Hopefully this is clear now.
One last thing. Wikipedia’s article continues “It is
constructed from the joint probability distribution of the
random variable that (presumably) generated the observations”.
When I said earlier that the definition of the Likelihood was
simply the PDF with its parameters considered as variables that
was only partially true. It is actually the joint PDF.
In this case we just considered a “joint” PDF with only one
part. The likelihood function is useful because it helps us
guess the parameters of a distribution given some samples from
it. Say we have IID samples , from a known
distribution with unknown parameters, and we want to find the
parameters which maximize the probability of having drawn this
sample. The parameters which maximize the likelihood function
are those parameters! If this isn’t clear, think back to the one
dimensional case and the previous figure.
Here is a simple example of this process (called a maximum
likelihood estimate) for three data points assumed to be drawn
from a Gaussian distribution
https://www.lairdstewart.com/blog/beware-pithy-rules.htmlBeware of Pithy Rules About Software2025-01-05T00:00:00Z
The root cause of a lot of bad code is the overuse of common
rules (e.g., DRY, YAGNI, “keep methods under X lines”). These
are well-intentioned and distill years of programming expertise.
However, even in a world where they’re right 90% of the time,
the 10% of times they’re wrong translates to technical debt
which compounds quickly. This isn’t to say their creators are at
fault; These rules are often introduced with disclaimers about
overuse. The problem is that these catchy sayings don’t have
room for disclaimers. After learning a new rule, new developers
may only remember the acronym and not any of its nuances. Senior
developers aren’t innocent either; During code review, it’s
easier to cite a rule than explain the underlying issue with the
code. Teachers don’t want to overwhelm students, so they may
give a blanket statement like “don’t use static methods”. There
is a direct relationship between the length of a piece of advice
and its value. Longer answers can provide context, edge cases,
and describe more sophisticated concepts. It shouldn’t be a
surprise that short, general statements can lead us astray.
“Methods should be shorter than X lines”
The professor of my software design course at Georgia Tech
suggested methods should be under five lines, and Clean
Code claims “The first rule of functions is that they
should be small. The second rule of functions is that they
should be smaller than that.” In my mind, this rule is just
a heuristic to remind us that methods should generally only have
a single “concept”. I argue that because the former is easier to
remember it gets used (and abused) more frequently. See It’s probably time to stop
recommending Clean Code for an example of how this can go
too far.
“Don’t repeat yourself”
In my first internship, I inherited a thousand-line R script
with code literally copy and pasted half a dozen times with
different hard-coded parameters. DRY is a powerful concept when
you first learn it, and I’ve met a number of data scientists who
could have learned it sooner. However, entry level software
engineers understand copy and pasting code is a red flag.
However, it can cause more harm than good in the form of
premature optimization and over-abstraction.
“Comments are a failure to express yourself through code”
Early on at my first job, I came across this saying in
Clean Code. It seemed reasonable, and my team already
used comments sparingly, so I accepted it at face value. Over my
first year, I wrote nearly no comments. I went so far as to
leave PR comments to explain confusing bits because I
internalized that putting it in the code was a failure. I’ve
since grown a much more favorable outlook on comments. The
ultimate irony is that, upon returning to the chapter on
comments in Clean Code, I agree almost entirely with
it. But because I only remembered this one saying, my outlook on
the topic was quite warped.
 1D-Chess,
Rowan Monk
1D-Chess,
Rowan Monk